parent
e5705bd6cc
commit
8692f05f14
123 changed files with 6012 additions and 59 deletions
{kind=link}
|
Before Width: | Height: | Size: 95 KiB After Width: | Height: | Size: 103 KiB |
@ -1,60 +1,9 @@ |
||||
# ACID Properties in PostgreSQL |
||||
# ACID |
||||
|
||||
ACID (Atomicity, Consistency, Isolation, and Durability) is a set of properties that guarantee database transactions are reliable and maintain data integrity in any system. PostgreSQL being a powerful relational database management system (RDBMS) fully conforms to these ACID properties, ensuring secure and robust transaction management in your applications. Let's take a closer look at each property: |
||||
ACID are the four properties of relational database systems that help in making sure that we are able to perform the transactions in a reliable manner. It's an acronym which refers to the presence of four properties: atomicity, consistency, isolation and durability |
||||
|
||||
## Atomicity |
||||
Visit the following resources to learn more: |
||||
|
||||
Atomicity refers to the "all or nothing" principle, in which each transaction is considered a single unit of work. If one part of the transaction fails, the entire transaction fails and the database remains unchanged. On the other hand, if all parts of the transaction are successful, they will be committed to the database as a whole. |
||||
|
||||
Example: |
||||
|
||||
```sql |
||||
BEGIN; |
||||
INSERT INTO accounts (name, balance) VALUES ('John', 1000); |
||||
UPDATE accounts SET balance = balance + 100 WHERE name = 'Jane'; |
||||
COMMIT; |
||||
``` |
||||
|
||||
In this transaction, if any statement fails, the entire transaction will be rolled back, ensuring that either both actions occur or none do. |
||||
|
||||
## Consistency |
||||
|
||||
Consistency ensures that a database starts in a consistent state and, after every transaction, remains consistent. This means that any transaction will bring the database from one consistent state to another, keeping data integrity in check. Consistency is achieved by following rules and constraints such as unique constraints, foreign key constraints, and others. |
||||
|
||||
Example: |
||||
|
||||
Suppose we have a rule that says the balance for any account cannot go below 0. A transaction that transfers money between two accounts should maintain this rule, ensuring consistency. |
||||
|
||||
## Isolation |
||||
|
||||
Isolation refers to the idea that different transactions should be separated from one another, hiding the intermediate states of a transaction from other concurrent transactions. This prevents one transaction from reading uncommitted data generated by other transactions. PostgreSQL supports multiple isolation levels, which determine the degree of isolation between transactions. |
||||
|
||||
Example: |
||||
|
||||
Transaction A: |
||||
```sql |
||||
BEGIN; |
||||
SELECT balance FROM accounts WHERE name = 'John'; |
||||
-- some other transaction occurs here |
||||
UPDATE accounts SET balance = balance - 100 WHERE name = 'John'; |
||||
COMMIT; |
||||
``` |
||||
|
||||
Transaction B, running concurrently: |
||||
```sql |
||||
BEGIN; |
||||
UPDATE accounts SET balance = balance + 100 WHERE name = 'Jane'; |
||||
COMMIT; |
||||
``` |
||||
|
||||
With proper isolation, Transaction A should not see the intermediate state of changes made by Transaction B until it is committed, preventing dirty reads or other anomalies. |
||||
|
||||
## Durability |
||||
|
||||
Durability ensures that once a transaction is committed, its changes to the database are permanent and will not be lost due to any system failure, crash or restart. PostgreSQL achieves durability by using a write-ahead log (WAL), which saves all transactional changes before they are written to the actual database. |
||||
|
||||
Example: |
||||
|
||||
If a server crashes right after a financial transaction is committed, like transferring money between accounts, the changes are still permanently stored and can be re-applied after the system restarts. |
||||
|
||||
In conclusion, ACID properties play a crucial role in maintaining the reliability and integrity of any database system, especially in a highly concurrent environment like PostgreSQL. Understanding these properties helps you to design better applications and ensure consistent and accurate data management. |
||||
- [What is ACID Compliant Database?](https://retool.com/blog/whats-an-acid-compliant-database/) |
||||
- [What is ACID Compliance?: Atomicity, Consistency, Isolation](https://fauna.com/blog/what-is-acid-compliance-atomicity-consistency-isolation) |
||||
- [ACID Explained: Atomic, Consistent, Isolated & Durable](https://www.youtube.com/watch?v=yaQ5YMWkxq4) |
||||
|
||||
@ -0,0 +1,54 @@ |
||||
# What Are Relational Databases? |
||||
|
||||
A **relational database** is a type of database that stores and organizes data in a structured way. It uses a structure |
||||
that allows data to be identified and accessed in relation to other data in the database. Data in a relational database |
||||
is stored in various data tables, each of which has a unique key identifying every row. |
||||
|
||||
|
||||
|
||||
Relational databases are made up of a set of tables with data that fits into a predefined category. Each table has at |
||||
least one data category in a column, and each row contains a certain data instance for the categories defined in the |
||||
columns. |
||||
|
||||
For example, consider an 'Employees' table: |
||||
|
||||
| EmployeeId | FirstName | LastName | Email | |
||||
|------------|-----------|----------|-----------------------| |
||||
| 1 | John | Doe | john.doe@example.com | |
||||
| 2 | Jane | Doe | jane.doe@example.com | |
||||
| 3 | Bob | Smith | bob.smith@example.com | |
||||
|
||||
In this table, 'EmployeeId', 'FirstName', 'LastName' and 'Email' are categories, and each row represents a specific |
||||
employee. |
||||
|
||||
## Relationships |
||||
|
||||
The term "relational database" comes from the concept of a relation—a set of tuples that the database organizes into |
||||
rows and columns. Each row in a table represents a relationship among a set of values. |
||||
|
||||
Relational databases use `keys` to create links between tables. A `primary key` is a unique identifier for a row of |
||||
data. A `foreign key` is a column or combination of columns used to establish and enforce a link between the data in two |
||||
tables. |
||||
|
||||
Consider an additional 'Orders' table: |
||||
|
||||
| OrderId | EmployeeId | Product | |
||||
|---------|------------|----------| |
||||
| 1 | 3 | Apples | |
||||
| 2 | 1 | Bananas | |
||||
| 3 | 2 | Cherries | |
||||
|
||||
In the 'Orders' table, 'EmployeeId' serves as the foreign key creating a relationship between 'Orders' and 'Employees'. |
||||
This allows queries that involve data in both tables, like "Find all orders placed by John Doe". |
||||
|
||||
```sql |
||||
SELECT Orders.OrderId, Orders.Product, Employees.FirstName, Employees.LastName |
||||
FROM Orders |
||||
INNER JOIN Employees ON Orders.EmployeeId = Employees.EmployeeId; |
||||
``` |
||||
|
||||
The above SQL code is an example of how to retrieve data from a relational database using a `JOIN` clause to combine |
||||
rows from two or more tables. |
||||
|
||||
Overall, relational databases provide a powerful mechanism for defining relationships within data and enabling efficient |
||||
data retrieval. |
||||
@ -0,0 +1,27 @@ |
||||
# RDBMS Benefits and Limitations |
||||
|
||||
Here are some of the benefits of using an RDBMS: |
||||
|
||||
- **Structured Data**: RDBMS allows data storage in a structured way, using rows and columns in tables. This makes it easy to manipulate the data using SQL (Structured Query Language), ensuring efficient and flexible usage. |
||||
|
||||
- **ACID Properties**: ACID stands for Atomicity, Consistency, Isolation, and Durability. These properties ensure reliable and safe data manipulation in a RDBMS, making it suitable for mission-critical applications. |
||||
|
||||
- **Normalization**: RDBMS supports data normalization, a process that organizes data in a way that reduces data redundancy and improves data integrity. |
||||
|
||||
- **Scalability**: RDBMSs generally provide good scalability options, allowing for the addition of more storage or computational resources as the data and workload grow. |
||||
|
||||
- **Data Integrity**: RDBMS provides mechanisms like constraints, primary keys, and foreign keys to enforce data integrity and consistency, ensuring that the data is accurate and reliable. |
||||
|
||||
- **Security**: RDBMSs offer various security features such as user authentication, access control, and data encryption to protect sensitive data. |
||||
|
||||
Here are some of the limitations of using an RDBMS: |
||||
|
||||
- **Complexity**: Setting up and managing an RDBMS can be complex, especially for large applications. It requires technical knowledge and skills to manage, tune, and optimize the database. |
||||
|
||||
- **Cost**: RDBMSs can be expensive, both in terms of licensing fees and the computational and storage resources they require. |
||||
|
||||
- **Fixed Schema**: RDBMS follows a rigid schema for data organization, which means any changes to the schema can be time-consuming and complicated. |
||||
|
||||
- **Handling of Unstructured Data**: RDBMSs are not suitable for handling unstructured data like multimedia files, social media posts, and sensor data, as their relational structure is optimized for structured data. |
||||
|
||||
- **Horizontal Scalability**: RDBMSs are not as easily horizontally scalable as NoSQL databases. Scaling horizontally, which involves adding more machines to the system, can be challenging in terms of cost and complexity. |
||||
@ -0,0 +1,43 @@ |
||||
# SQL vs NoSQL |
||||
|
||||
When discussing databases, it's essential to understand the difference between SQL and NoSQL databases, as each has its own set of advantages and limitations. In this section, we'll briefly compare and contrast the two, so you can determine which one suits your needs better. |
||||
|
||||
## SQL Databases |
||||
|
||||
SQL (Structured Query Language) databases are also known as relational databases. They have a predefined schema, and data is stored in tables consisting of rows and columns. SQL databases follow the ACID (Atomicity, Consistency, Isolation, Durability) properties to ensure reliable transactions. Some popular SQL databases include MySQL, PostgreSQL, and Microsoft SQL Server. |
||||
|
||||
**Advantages of SQL databases:** |
||||
|
||||
- **Predefined schema**: Ideal for applications with a fixed structure. |
||||
- **ACID transactions**: Ensures data consistency and reliability. |
||||
- **Support for complex queries**: Rich SQL queries can handle complex data relationships and aggregation operations. |
||||
- **Scalability**: Vertical scaling by adding more resources to the server (e.g., RAM, CPU). |
||||
|
||||
**Limitations of SQL databases:** |
||||
|
||||
- **Rigid schema**: Data structure updates are time-consuming and can lead to downtime. |
||||
- **Scaling**: Difficulties in horizontal scaling and sharding of data across multiple servers. |
||||
- **Not well-suited for hierarchical data**: Requires multiple tables and JOINs to model tree-like structures. |
||||
|
||||
## NoSQL Databases |
||||
|
||||
NoSQL (Not only SQL) databases refer to non-relational databases, which don't follow a fixed schema for data storage. Instead, they use a flexible and semi-structured format like JSON documents, key-value pairs, or graphs. MongoDB, Cassandra, Redis, and Couchbase are some popular NoSQL databases. |
||||
|
||||
**Advantages of NoSQL databases:** |
||||
|
||||
- **Flexible schema**: Easily adapts to changes without disrupting the application. |
||||
- **Scalability**: Horizontal scaling by partitioning data across multiple servers (sharding). |
||||
- **Fast**: Designed for faster read and writes, often with a simpler query language. |
||||
- **Handling large volumes of data**: Better suited to managing big data and real-time applications. |
||||
- **Support for various data structures**: Different NoSQL databases cater to various needs, like document, graph, or key-value stores. |
||||
|
||||
**Limitations of NoSQL databases:** |
||||
|
||||
- **Limited query capabilities**: Some NoSQL databases lack complex query and aggregation support or use specific query languages. |
||||
- **Weaker consistency**: Many NoSQL databases follow the BASE (Basically Available, Soft state, Eventual consistency) properties that provide weaker consistency guarantees than ACID-compliant databases. |
||||
|
||||
## MongoDB: A NoSQL Database |
||||
|
||||
This guide focuses on MongoDB, a popular NoSQL database that uses a document-based data model. MongoDB has been designed with flexibility, performance, and scalability in mind. With its JSON-like data format (BSON) and powerful querying capabilities, MongoDB is an excellent choice for modern applications dealing with diverse and large-scale data. |
||||
|
||||
- [NoSQL vs. SQL Databases](https://www.mongodb.com/nosql-explained/nosql-vs-sql) |
||||
@ -0,0 +1,18 @@ |
||||
# Introduction |
||||
|
||||
SQL, which stands for Structured Query Language, is a programming language that is used to communicate with and manage databases. SQL is a standard language for manipulating data held in relational database management systems (RDBMS), or for stream processing in a relational data stream management system (RDSMS). It was first developed in the 1970s by IBM. |
||||
|
||||
SQL consists of several components, each serving their own unique purpose in database communication: |
||||
|
||||
- **Queries:** This is the component that allows you to retrieve data from a database. The SELECT statement is most commonly used for this purpose. |
||||
- **Data Definition Language (DDL):** It lets you to create, alter, or delete databases and their related objects like tables, views, etc. Commands include CREATE, ALTER, DROP, and TRUNCATE. |
||||
- **Data Manipulation Language (DML):** It lets you manage data within database objects. These commands include SELECT, INSERT, UPDATE, and DELETE. |
||||
- **Data Control Language (DCL):** It includes commands like GRANT and REVOKE, which primarily deal with rights, permissions and other control-level management tasks for the database system. |
||||
|
||||
SQL databases come in a number of forms, such as Oracle Database, Microsoft SQL Server, and MySQL. Despite their many differences, all SQL databases utilise the same language commands - SQL. |
||||
|
||||
Learn more about SQL from the following resources: |
||||
|
||||
- [SQL Tutorial - Mode](https://mode.com/sql-tutorial/) |
||||
- [SQL Tutorial](https://www.sqltutorial.org/) |
||||
- [SQL Tutorial - W3Schools](https://www.w3schools.com/sql/default.asp) |
||||
@ -0,0 +1,60 @@ |
||||
# SQL keywords |
||||
|
||||
SQL employs a number of standard command keywords that are integral to interact with databases. Keywords in SQL provide |
||||
instructions as to what action should be performed. |
||||
|
||||
Here are some of the primary SQL keywords: |
||||
|
||||
**SELECT**: This keyword retrieves data from a database. For example, |
||||
|
||||
```sql |
||||
SELECT * FROM Customers; |
||||
``` |
||||
|
||||
In the above statement `*` indicates that all records should be retrieved from the `Customers` table. |
||||
|
||||
**FROM**: Used in conjunction with `SELECT` to specify the table from which to fetch data. |
||||
|
||||
**WHERE**: Used to filter records. Incorporating a WHERE clause, you might specify conditions that must be met. For |
||||
example, |
||||
|
||||
```sql |
||||
SELECT * FROM Customers WHERE Country='Germany'; |
||||
``` |
||||
|
||||
**INSERT INTO**: This command is used to insert new data into a database. |
||||
|
||||
```sql |
||||
INSERT INTO Customers (CustomerID, CustomerName, ContactName, Address, City, PostalCode, Country) |
||||
VALUES ('Cardinal','Tom B. Erichsen','Skagen 21','Stavanger','4006','Norway'); |
||||
``` |
||||
|
||||
**UPDATE**: This keyword updates existing data within a table. For example, |
||||
|
||||
```sql |
||||
UPDATE Customers SET ContactName='Alfred Schmidt', City='Frankfurt' WHERE CustomerID=1; |
||||
``` |
||||
|
||||
**DELETE**: This command removes one or more records from a table. For example, |
||||
|
||||
```sql |
||||
DELETE FROM Customers WHERE CustomerName='Alfreds Futterkiste'; |
||||
``` |
||||
|
||||
**CREATE DATABASE**: As implied by its name, this keyword creates a new database. |
||||
|
||||
```sql |
||||
CREATE DATABASE mydatabase; |
||||
``` |
||||
|
||||
**ALTER DATABASE**, **DROP DATABASE**, **CREATE TABLE**, **ALTER TABLE**, **DROP TABLE**: These keywords are used to |
||||
modify databases and tables. |
||||
|
||||
Remember that SQL is not case sensitive, meaning keywords can be written in lower case. The convention is to write them |
||||
in ALL CAPS for readability. There are many more keywords in SQL, but these are some of the most common. |
||||
|
||||
Learn more about SQL from the following resources: |
||||
|
||||
- [SQL Tutorial - Mode](https://mode.com/sql-tutorial/) |
||||
- [SQL Tutorial](https://www.sqltutorial.org/) |
||||
- [SQL Tutorial - W3Schools](https://www.w3schools.com/sql/default.asp) |
||||
@ -0,0 +1,82 @@ |
||||
# Data Types |
||||
|
||||
SQL data types define the type of data that can be stored in a database table's column. Depending on the DBMS, the names |
||||
of the data types can differ slightly. Here are the general types: |
||||
|
||||
## INT |
||||
|
||||
`INT` is used for whole numbers. For example: |
||||
|
||||
```sql |
||||
CREATE TABLE Employees ( |
||||
ID INT, |
||||
Name VARCHAR(30) |
||||
); |
||||
``` |
||||
|
||||
## DECIMAL |
||||
|
||||
`DECIMAL` is used for decimal and fractional numbers. For example: |
||||
|
||||
```sql |
||||
CREATE TABLE Items ( |
||||
ID INT, |
||||
Price DECIMAL(5,2) |
||||
); |
||||
``` |
||||
|
||||
## CHAR |
||||
|
||||
`CHAR` is used for fixed-length strings. For example: |
||||
|
||||
```sql |
||||
CREATE TABLE Employees ( |
||||
ID INT, |
||||
Initial CHAR(1) |
||||
); |
||||
``` |
||||
|
||||
## VARCHAR |
||||
|
||||
`VARCHAR` is used for variable-length strings. For example: |
||||
|
||||
```sql |
||||
CREATE TABLE Employees ( |
||||
ID INT, |
||||
Name VARCHAR(30) |
||||
); |
||||
``` |
||||
|
||||
## DATE |
||||
|
||||
`DATE` is used for dates in the format (`YYYY-MM-DD`). |
||||
|
||||
```sql |
||||
CREATE TABLE Employees ( |
||||
ID INT, |
||||
BirthDate DATE |
||||
); |
||||
``` |
||||
|
||||
## DATETIME |
||||
|
||||
`DATETIME` is used for date and time values in the format (`YYYY-MM-DD HH:MI:SS`). |
||||
|
||||
```sql |
||||
CREATE TABLE Orders ( |
||||
ID INT, |
||||
OrderDate DATETIME |
||||
); |
||||
``` |
||||
|
||||
## BINARY |
||||
|
||||
`BINARY` is used for binary strings. |
||||
|
||||
## BOOLEAN |
||||
|
||||
`BOOLEAN` is used for boolean values (`TRUE` or `FALSE`). |
||||
|
||||
**Remember**, the specific syntax for creating tables and defining column data types can vary slightly depending upon |
||||
the SQL database you are using (MySQL, PostgreSQL, SQL Server, SQLite, Oracle, etc.), but the general concept and |
||||
organization of data types is cross-platform. |
||||
@ -0,0 +1,61 @@ |
||||
# Operators |
||||
|
||||
SQL operators are used to perform operations like comparisons and arithmetic calculations. They are very crucial in |
||||
forming queries. SQL operators are divided into the following types: |
||||
|
||||
1. **Arithmetic Operators**: These are used to perform mathematical operations. Here is a list of these operators: |
||||
|
||||
- `+` : Addition |
||||
- `-` : Subtraction |
||||
- `*` : Multiplication |
||||
- `/` : Division |
||||
- `%` : Modulus |
||||
|
||||
Example: |
||||
|
||||
```sql |
||||
SELECT product, price, (price * 0.18) as tax |
||||
FROM products; |
||||
``` |
||||
|
||||
2. **Comparison Operators**: These are used in the where clause to compare one expression with another. Some of these |
||||
operators are: |
||||
|
||||
- `=` : Equal |
||||
- `!=` or `<>` : Not equal |
||||
- `>` : Greater than |
||||
- `<` : Less than |
||||
- `>=`: Greater than or equal |
||||
- `<=`: Less than or equal |
||||
|
||||
Example: |
||||
|
||||
```sql |
||||
SELECT name, age |
||||
FROM students |
||||
WHERE age > 18; |
||||
``` |
||||
|
||||
3. **Logical Operators**: They are used to combine the result set of two different component conditions. These include: |
||||
|
||||
- `AND`: Returns true if both components are true. |
||||
- `OR` : Returns true if any one of the component is true. |
||||
- `NOT`: Returns the opposite boolean value of the condition. |
||||
|
||||
Example: |
||||
|
||||
```sql |
||||
SELECT * |
||||
FROM employees |
||||
WHERE salary > 50000 AND age < 30; |
||||
``` |
||||
|
||||
4. **Bitwise Operators**: These perform bit-level operations on the inputs. Here is a list of these operators: |
||||
|
||||
- `&` : Bitwise AND |
||||
- `|` : Bitwise OR |
||||
- `^` : Bitwise XOR |
||||
|
||||
Bitwise operators are much less commonly used in SQL than the other types of operators. |
||||
|
||||
Remember, the datatype of the result is dependent on the types of the operands. |
||||
@ -0,0 +1,68 @@ |
||||
# Basic SQL Syntax |
||||
|
||||
SQL, or Structured Query Language, uses a specific set of commands to interact with a database. It includes the use of keyword-like statements to accomplish several tasks such as creating, deleting, or modifying tables, retrieving, inserting, or modifying data. |
||||
|
||||
The `SELECT` statement is used to retrieve data from a database. The data returned is stored in a result table, called the result-set. |
||||
|
||||
```sql |
||||
SELECT column1, column2 FROM table_name; |
||||
``` |
||||
|
||||
The `INSERT INTO` statement is used to insert new rows of data in a table. |
||||
|
||||
```sql |
||||
INSERT INTO table_name (column1, column2, column3) |
||||
VALUES (value1, value2, value3); |
||||
``` |
||||
|
||||
The `UPDATE` statement is used to modify existing records in a table. |
||||
|
||||
```sql |
||||
UPDATE table_name |
||||
SET column1 = value1, column2 = value2 |
||||
WHERE condition; |
||||
``` |
||||
|
||||
The `DELETE` statement is used to remove rows from a table. |
||||
|
||||
```sql |
||||
DELETE FROM table_name WHERE condition; |
||||
``` |
||||
|
||||
The `CREATE TABLE` statement is used to create a new table in a database. |
||||
|
||||
```sql |
||||
CREATE TABLE table_name ( |
||||
column1 datatype constraints, |
||||
column2 datatype constraints, |
||||
column3 datatype constraints |
||||
); |
||||
``` |
||||
|
||||
The `ALTER TABLE ` statement is used to add, delete/drop or modify columns in the existing table. It is also used to add and drop constraints on the existing table. |
||||
|
||||
```sql |
||||
-- To add a column |
||||
ALTER TABLE table_name |
||||
ADD column_name datatype; |
||||
|
||||
-- To delete/drop column |
||||
ALTER TABLE table_name |
||||
DROP COLUMN column_name; |
||||
|
||||
-- To modify existing column |
||||
ALTER TABLE table_name |
||||
MODIFY COLUMN column_name datatype; |
||||
``` |
||||
|
||||
The `DROP TABLE` statement is used to drop an existing table in a database. |
||||
|
||||
```sql |
||||
DROP TABLE table_name; |
||||
``` |
||||
|
||||
Learn more about SQL from the following resources: |
||||
|
||||
- [SQL Tutorial - Mode](https://mode.com/sql-tutorial/) |
||||
- [SQL Tutorial](https://www.sqltutorial.org/) |
||||
- [SQL Tutorial - W3Schools](https://www.w3schools.com/sql/default.asp) |
||||
@ -0,0 +1,54 @@ |
||||
# SELECT |
||||
|
||||
The `SELECT` statement is used in SQL to pick out specific data from a database. In other words, it is used to select from the database what you would like to display. The syntax for the `SELECT` statement is fairly straightforward: |
||||
|
||||
```sql |
||||
SELECT column(s) |
||||
FROM table |
||||
WHERE condition; |
||||
``` |
||||
|
||||
- `column(s)`: Enter the name(s) of the column(s) that you want to display. |
||||
- `table`: The name of the table from where you want to retrieve data. |
||||
- `WHERE`: Optional. This is a filter to display only the rows where this condition is true. |
||||
|
||||
For instance, if you wanted to select all data from the "Customers" table, your query would look like this: |
||||
|
||||
```sql |
||||
SELECT * |
||||
FROM Customers; |
||||
``` |
||||
In the above code, the asterisk `*` denotes "all". This will retrieve all of the data in the "Customers" table. |
||||
|
||||
If you want to select only the "FirstName" and "LastName" columns from the "Customers" table, your query would look like this: |
||||
|
||||
```sql |
||||
SELECT FirstName, LastName |
||||
FROM Customers; |
||||
``` |
||||
|
||||
You can also filter using the `WHERE` clause. For example, selecting only the customers who are from "Germany": |
||||
|
||||
```sql |
||||
SELECT * |
||||
FROM Customers |
||||
WHERE Country='Germany'; |
||||
``` |
||||
|
||||
Finally, you can also sort the results using the `ORDER BY` keyword: |
||||
|
||||
```sql |
||||
SELECT * |
||||
FROM Customers |
||||
ORDER BY Country; |
||||
``` |
||||
|
||||
This will sort the output in ascending order by the Country column. To sort in descending order, you would add the `DESC` keyword: |
||||
|
||||
```sql |
||||
SELECT * |
||||
FROM Customers |
||||
ORDER BY Country DESC; |
||||
``` |
||||
|
||||
These are the very basics of the `SELECT` statement in SQL, which is a vital part of working with databases. |
||||
@ -0,0 +1,37 @@ |
||||
# INSERT |
||||
|
||||
The `INSERT` statement in SQL is used to add new rows of data to a table in the database. There are three forms of the `INSERT` statement: `INSERT INTO` values, `INSERT INTO` set, and `INSERT INTO` select. |
||||
|
||||
## `INSERT INTO` values |
||||
|
||||
The basic syntax for `INSERT INTO` values: |
||||
|
||||
```sql |
||||
INSERT INTO table_name (column1, column2, column3, ...) |
||||
VALUES (value1, value2, value3, ...); |
||||
``` |
||||
This form of the `INSERT` statement specifies both the column names and the values to be inserted. |
||||
|
||||
## `INSERT INTO` set |
||||
|
||||
In this form, you're able to insert data using the `SET` keyword. Here, you specify each column you want to insert data into, and then the data for that column. |
||||
|
||||
```sql |
||||
INSERT INTO table_name |
||||
SET column1 = value1, column2 = value2, ...; |
||||
``` |
||||
|
||||
## `INSERT INTO` select |
||||
|
||||
The `INSERT INTO SELECT` statement is used to copy data from one table and insert it into another table. Or, to insert data into specific columns from another table. |
||||
|
||||
```sql |
||||
INSERT INTO table_name1 (column1, column2, column3, ...) |
||||
SELECT column1, column2, column3, ... |
||||
FROM table_name2 |
||||
WHERE condition; |
||||
``` |
||||
|
||||
In all cases, if you're inserting data into a table where some columns have default values, you don't need to specify those columns in your `INSERT INTO` statement. |
||||
|
||||
Note: Be careful when inserting data into a database as SQL does not have a confirm command. So once you execute the insert statement, the records are inserted, and you can't undo the operation. |
||||
@ -0,0 +1,45 @@ |
||||
# UPDATE |
||||
|
||||
The SQL `UPDATE` statement is used to modify the existing data in a database. This statement is very useful when you need to change the values assigned to specific fields in an existing row or set of rows. |
||||
|
||||
The general syntax for the UPDATE statement is as follows: |
||||
|
||||
```sql |
||||
UPDATE table_name |
||||
SET column1 = value1, column2 = value2, ... |
||||
WHERE condition; |
||||
``` |
||||
|
||||
- `table_name`: The name of the table where an update will be performed. |
||||
- `SET`: This clause specifies the column name and the new value that it should be updated to. |
||||
- `column1, column2, ...`: The column names in the table. |
||||
- `value1, value2, ...`: The new values that you want to record into the database. |
||||
- `WHERE`: This clause specifies the conditions that identify which row(s) to update. |
||||
|
||||
## Example Usage |
||||
|
||||
Here's an example that might provide some clarity. For an imaginary `Employees` table: |
||||
|
||||
| EmployeeID | Name | Position | Salary | |
||||
|------------|---------|----------|--------| |
||||
| 1 | Jane | Manager | 50000 | |
||||
| 2 | John | Clerk | 30000 | |
||||
| 3 | Bob | Engineer | 40000 | |
||||
|
||||
If you want to increase Bob's salary by $5000, you would use: |
||||
|
||||
```sql |
||||
UPDATE Employees |
||||
SET Salary = 45000 |
||||
WHERE EmployeeID = 3; |
||||
``` |
||||
|
||||
This would permanently change the data in the `Employees` table: |
||||
|
||||
| EmployeeID | Name | Position | Salary | |
||||
|------------|---------|----------|--------| |
||||
| 1 | Jane | Manager | 50000 | |
||||
| 2 | John | Clerk | 30000 | |
||||
| 3 | Bob | Engineer | 45000 | |
||||
|
||||
Always be careful with the `UPDATE` statement; if you forget the `WHERE` clause, you will update all the rows in the table. |
||||
@ -0,0 +1,30 @@ |
||||
# DELETE |
||||
|
||||
The `DELETE` statement in SQL helps you remove existing records from a database. However, keep in mind, it is a destructive operation and may permanently erase data from your database. |
||||
|
||||
With the `DELETE` statement, you can perform the following: |
||||
|
||||
1. **Delete All Rows:** |
||||
|
||||
The `DELETE` statement without a `WHERE` clause deletes all rows in a table. This operation is irreversible. |
||||
|
||||
Example: |
||||
```sql |
||||
DELETE FROM table_name; |
||||
``` |
||||
This SQL statement deletes all the records from `table_name`. |
||||
|
||||
2. **Delete Specific Rows:** |
||||
|
||||
When combined with the `WHERE` clause, the `DELETE` SQL statement erases specific rows that meet the condition. |
||||
|
||||
Example: |
||||
```sql |
||||
DELETE FROM table_name WHERE condition; |
||||
``` |
||||
This instance of the `DELETE` statement deletes records from `table_name` the place where the given `condition` matches. |
||||
|
||||
It's crucial to use `DELETE` cautiously because it has the potential to either erase certain important rows or entirely empty the table. |
||||
|
||||
|
||||
*Note: The deletion made by the "DELETE" statement is permanent and cannot be undone. Always ensure to have a backup before running a DELETE query, especially when it is on a production database.* |
||||
@ -0,0 +1 @@ |
||||
# Statements |
||||
@ -0,0 +1,52 @@ |
||||
# Create Table |
||||
|
||||
The `CREATE TABLE` statement in SQL is a Data Definition Language (DDL) command used to create a new table in the database. |
||||
|
||||
## SQL CREATE TABLE Syntax |
||||
|
||||
The syntax for SQL `CREATE TABLE` is as follows: |
||||
|
||||
```sql |
||||
CREATE TABLE table_name ( |
||||
column1 datatype, |
||||
column2 datatype, |
||||
column3 datatype, |
||||
.... |
||||
); |
||||
``` |
||||
|
||||
- `table_name` is the name of the table that you want to create. |
||||
- `column1, column2,...` are the columns in the table. |
||||
- `datatype` is the data type for the column, such as varchar, int, date, etc. |
||||
|
||||
## SQL CREATE TABLE Example |
||||
|
||||
Here is an example of the `CREATE TABLE` statement: |
||||
|
||||
```sql |
||||
CREATE TABLE Employees ( |
||||
ID int, |
||||
Name varchar(255), |
||||
Salary int, |
||||
Department varchar(255), |
||||
Position varchar(255) |
||||
); |
||||
``` |
||||
|
||||
This SQL command creates a new table named `Employees` with five columns, named 'ID', 'Name', 'Salary', 'Department', and 'Position'. The data types are int for the 'ID' and 'Salary', and varchar(255) for the others. |
||||
|
||||
## SQL CREATE TABLE with NOT NULL |
||||
|
||||
The `NOT NULL` constraint enforces a column to not accept null values. When creating a new table, you can add this constraint. Here is a practical example: |
||||
|
||||
```sql |
||||
CREATE TABLE Employees ( |
||||
ID int NOT NULL, |
||||
Name varchar(255) NOT NULL, |
||||
Salary int, |
||||
Department varchar(255), |
||||
Position varchar(255) |
||||
); |
||||
``` |
||||
|
||||
In the example above, the 'ID' and 'Name' must always have a value. They cannot be unassigned or undefined. |
||||
@ -0,0 +1,69 @@ |
||||
# Alter Table |
||||
|
||||
The `ALTER TABLE` command in SQL is used to add, delete/drop, or modify columns in an existing table. It's also useful for adding and dropping constraints such as primary key, foreign key, etc. |
||||
|
||||
## Add Column |
||||
|
||||
A single column can be added using the following syntax: |
||||
|
||||
```sql |
||||
ALTER TABLE tableName |
||||
ADD columnName datatype; |
||||
``` |
||||
|
||||
To add more than one column: |
||||
|
||||
```sql |
||||
ALTER TABLE tableName |
||||
ADD (columnName1 datatype, |
||||
columnName2 datatype, |
||||
... |
||||
); |
||||
``` |
||||
|
||||
## Drop Column |
||||
|
||||
To drop a single column: |
||||
|
||||
```sql |
||||
ALTER TABLE tableName |
||||
DROP COLUMN columnName; |
||||
``` |
||||
|
||||
To drop multiple columns: |
||||
|
||||
```sql |
||||
ALTER TABLE tableName |
||||
DROP (columnName1, |
||||
columnName2, |
||||
... |
||||
); |
||||
``` |
||||
|
||||
## Modify Column |
||||
|
||||
To modify the datatype of a column: |
||||
|
||||
```sql |
||||
ALTER TABLE tableName |
||||
ALTER COLUMN columnName TYPE newDataType; |
||||
``` |
||||
|
||||
## Add/Drop Constraints |
||||
|
||||
To add constraints: |
||||
|
||||
```sql |
||||
ALTER TABLE tableName |
||||
ADD CONSTRAINT constraintName |
||||
PRIMARY KEY (column1, column2, ... column_n); |
||||
``` |
||||
|
||||
To drop constraints: |
||||
|
||||
```sql |
||||
ALTER TABLE tableName |
||||
DROP CONSTRAINT constraintName; |
||||
``` |
||||
|
||||
In conclusion, `ALTER TABLE` in SQL lets you alter the structure of an existing table. This is a powerful command that lets you dynamically add, modify, and delete columns as well as the constraints placed on them. It ensures you are more flexible in dealing with changing data storage requirements. |
||||
@ -0,0 +1,39 @@ |
||||
# Truncate Table |
||||
|
||||
The `TRUNCATE TABLE` statement is a Data Definition Language (DDL) operation that is used to mark the extents of a table for deallocation (empty for reuse). The result of this operation quickly removes all data from a table, typically bypassing a number of integrity enforcing mechanisms intended to protect data (like triggers). |
||||
|
||||
It effectively eliminates all records in a table, but not the table itself. Unlike the `DELETE` statement, `TRUNCATE TABLE` does not generate individual row delete statements, so the usual overhead for logging or locking does not apply. |
||||
|
||||
## Syntax |
||||
|
||||
In SQL, the `TRUNCATE TABLE` statement is quite simple: |
||||
|
||||
```sql |
||||
TRUNCATE TABLE table_name; |
||||
``` |
||||
|
||||
In this command, "table_name" refers to the name of the table you wish to clear. |
||||
|
||||
## Example |
||||
|
||||
If you have a table named `Orders` and you want to delete all its records, you would use: |
||||
|
||||
```sql |
||||
TRUNCATE TABLE Orders; |
||||
``` |
||||
|
||||
After executing this statement, the `Orders` table would still exist, but it would be empty. |
||||
|
||||
Remember, while `TRUNCATE TABLE` is faster and uses fewer system and transaction log resources than `DELETE`, it does not invoke triggers and cannot be rolled back, so use with caution. |
||||
|
||||
## Limitations |
||||
|
||||
Truncate preserves the structure of the table for future use. But you can't truncate a table that: |
||||
|
||||
- Is referenced by a FOREIGN KEY constraint. (You can truncate a table that has a foreign key that references itself.) |
||||
- Participates in an indexed view. |
||||
- Is published by using transactional replication or merge replication. |
||||
|
||||
If you try to truncate a table with a foreign key constraint, SQL Server will prevent you from doing so and you will have to use the `DELETE` statement instead. |
||||
|
||||
For partitioned tables, `TRUNCATE TABLE` removes all rows from all partitions. The operation is not allowed if the table contains any LOB columns - `varchar(max), nvarchar(max), varbinary(max), text, ntext, image, xml`, or if the table contains any filestream columns or spatial geo, geography, geometry, and hierarchyid data type columns, or any columns of CLR user-defined data types. |
||||
@ -0,0 +1,43 @@ |
||||
# Data Definition Language (DDL) |
||||
|
||||
Data Definition Language (DDL) is a subset of SQL. Its primary function is to create, modify, and delete database structures but not data. The commands in DDL are: |
||||
|
||||
1. `CREATE`: This command is used to create the database or its objects (like table, index, function, views, store procedure, and triggers). |
||||
|
||||
```sql |
||||
CREATE TABLE table_name ( |
||||
column1 data_type(size), |
||||
column2 data_type(size), |
||||
... |
||||
); |
||||
``` |
||||
|
||||
2. `DROP`: This command is used to delete an existing database or table. |
||||
|
||||
```sql |
||||
DROP TABLE table_name; |
||||
``` |
||||
|
||||
3. `ALTER`: This is used to alter the structure of the database. It is used to add, delete/drop or modify columns in an existing table. |
||||
|
||||
```sql |
||||
ALTER TABLE table_name ADD column_name datatype; |
||||
ALTER TABLE table_name DROP COLUMN column_name; |
||||
ALTER TABLE table_name MODIFY COLUMN column_name datatype(size); |
||||
``` |
||||
|
||||
4. `TRUNCATE`: This is used to remove all records from a table, including all spaces allocated for the records which are removed. |
||||
|
||||
```sql |
||||
TRUNCATE TABLE table_name; |
||||
``` |
||||
|
||||
5. `RENAME`: This is used to rename an object in the database. |
||||
|
||||
```sql |
||||
RENAME TABLE old_table_name TO new_table_name; |
||||
``` |
||||
|
||||
Remember: In DDL operations, `COMMIT` and `ROLLBACK` statement cannot be performed because the MySQL engine automatically commits the changes. |
||||
|
||||
Remember to replace `table_name`, `column_name`, `datatype(size)`, `old_table_name`, and `new_table_name` in the examples above with your actual table names, column names, data types and sizes, and the old or new table names you want to specify. |
||||
@ -0,0 +1,77 @@ |
||||
# SELECT |
||||
|
||||
The `SELECT` statement in SQL is majorly used for fetching data from the database. It is one of the most essential elements of SQL. |
||||
|
||||
## Syntax |
||||
|
||||
Here's how your `SELECT` command will look like: |
||||
|
||||
```sql |
||||
SELECT column1, column2, ... |
||||
FROM table_name; |
||||
``` |
||||
If you want to select all the columns of a table, you can use `*` like this: |
||||
```sql |
||||
SELECT * FROM table_name; |
||||
``` |
||||
## Example |
||||
|
||||
For instance, consider we have a table `EMPLOYEES` with columns `name`, `designation`, and `salary`. We can use `SELECT` in the following way: |
||||
|
||||
```sql |
||||
SELECT name, designation FROM EMPLOYEES; |
||||
``` |
||||
This will retrieve all the names and designations of all employees from the table `EMPLOYEES`. |
||||
|
||||
## SELECT DISTINCT |
||||
|
||||
The `SELECT DISTINCT` statement is used to return only distinct (different) values. The DISTINCT keyword eliminates duplicate records from the results. |
||||
|
||||
Here's how you can use it: |
||||
|
||||
```sql |
||||
SELECT DISTINCT column1, column2, ... |
||||
FROM table_name; |
||||
``` |
||||
|
||||
For example, if we want to select all unique designations from the `EMPLOYEES` table, the query will look like this: |
||||
|
||||
```sql |
||||
SELECT DISTINCT designation FROM EMPLOYEES; |
||||
``` |
||||
|
||||
## SELECT WHERE |
||||
|
||||
`SELECT` statement combined with `WHERE` gives us the ability to filter records based on a condition. |
||||
|
||||
Syntax: |
||||
|
||||
```sql |
||||
SELECT column1, column2, ... |
||||
FROM table_name |
||||
WHERE condition; |
||||
``` |
||||
For example, to select employees with salary more than 50000, you can use this query: |
||||
|
||||
```sql |
||||
SELECT * FROM EMPLOYEES WHERE salary > 50000; |
||||
``` |
||||
|
||||
## SELECT ORDER BY |
||||
|
||||
Using `SELECT` statement in conjunction with `ORDER BY`, we can sort the result-set in ascending or descending order. |
||||
|
||||
Syntax: |
||||
|
||||
```sql |
||||
SELECT column1, column2, ... |
||||
FROM table_name |
||||
ORDER BY column ASC|DESC; |
||||
``` |
||||
For example, to select all employees and order them by their name in ascending fashion: |
||||
|
||||
```sql |
||||
SELECT * FROM EMPLOYEES ORDER BY name ASC; |
||||
``` |
||||
|
||||
Remember that the default sort order is ascending if the ASC|DESC parameter is not defined. |
||||
@ -0,0 +1,47 @@ |
||||
# FROM |
||||
|
||||
The `FROM` clause in SQL specifies the tables from which the retrieval should be made. It is an integral part of `SELECT` statements and variants of `SELECT` like `SELECT INTO` and `SELECT WHERE`. `FROM` can be used to join tables as well. |
||||
|
||||
Typically, `FROM` is followed by space delimited list of tables in which the SELECT operation is to be executed. If you need to pull data from multiple tables, you would separate each table with a comma. |
||||
|
||||
Here are some examples: |
||||
|
||||
**Example 1 - Simple Usage** |
||||
|
||||
If you've a table called `employees`, you can select all employees' data like this: |
||||
|
||||
```sql |
||||
SELECT * |
||||
FROM employees; |
||||
``` |
||||
In this example, `*` means "all columns". So, `SELECT * FROM employees;` will retrieve all data from the `employees` table. |
||||
|
||||
**Example 2 - FROM with Multiple Tables** |
||||
|
||||
If you've multiple tables, say `employees` and `departments`, and you want to select data from both, you can do the following: |
||||
|
||||
```sql |
||||
SELECT employees.name, departments.department |
||||
FROM employees, departments |
||||
WHERE employees.dept_id = departments.dept_id; |
||||
``` |
||||
|
||||
In this example, the `FROM` clause is following by two tables: `employees` and `departments`. `employees.name` and `departments.department` indicate that we're selecting the `name` column from the `employees` table and the `department` column from the `departments` table. |
||||
|
||||
Remember, always respect the order of operations in SQL. The `FROM` clause works only after tables are identified. |
||||
|
||||
In complex SQL queries where you might need to pull data from multiple tables, aliases are used to temporarily rename the tables within the individual SQL statement. |
||||
|
||||
**Example 3 - FROM with Aliases** |
||||
|
||||
Below is an example of a `FROM` clause with aliases: |
||||
|
||||
```sql |
||||
SELECT e.name, d.department |
||||
FROM employees AS e, departments AS d |
||||
WHERE e.dept_id = d.dept_id; |
||||
``` |
||||
|
||||
In this example, `employees` and `departments` tables are termed as `e` and `d` respectively. |
||||
|
||||
That's it! Remember that `FROM` is not limited only to `SELECT`. It is applicable to `UPDATE` and `DELETE` operations as well. |
||||
@ -0,0 +1,48 @@ |
||||
# INSERT |
||||
|
||||
The "INSERT" statement is used to add new rows of data to a table in a database. There are two main forms of the INSERT command: `INSERT INTO` which, if columns are not named, expects a full set of columns, and `INSERT INTO table_name (column1, column2, ...)` where only named columns will be filled with data. |
||||
|
||||
## Usage |
||||
|
||||
1. **Insert full set of columns:** |
||||
|
||||
Code example: |
||||
|
||||
```sql |
||||
INSERT INTO table_name |
||||
VALUES (value1, value2, ..., valueN); |
||||
``` |
||||
|
||||
In the example above, you need to provide values for all columns available in the table. |
||||
|
||||
2. **Selectively insert data:** |
||||
|
||||
Code example: |
||||
|
||||
```sql |
||||
INSERT INTO table_name (column1, column2, ..., columnN) |
||||
VALUES (value1, value2, ..., valueN); |
||||
``` |
||||
|
||||
Here, you only provide values for certain columns of the table. Other columns will take on their default values (if any). |
||||
|
||||
3. **Insert data from another table:** |
||||
|
||||
Another useful form of the `INSERT` command is `INSERT INTO SELECT`, which allows you to copy data from one table and add it into another table. |
||||
|
||||
Code example: |
||||
|
||||
```sql |
||||
INSERT INTO table1 (column1, column2, ... , columnN) |
||||
SELECT column1, column2, ... , columnN |
||||
FROM table2 |
||||
WHERE condition; |
||||
``` |
||||
|
||||
In this scenario, `table2` should already have the data we need and the WHERE clause can be used to select only those rows that satisfy certain conditions. |
||||
|
||||
> Note: The crucial point is that your columns in both SELECT and INSERT INTO command must be in same order and their datatypes must be compatible. |
||||
> |
||||
> Kindly ensure that database table has enough space to hold inserted data, else it will resulting in OVERFLOW error. |
||||
|
||||
**Note**: Always make sure to provide correct and compatible data types for the columns. The SQL engine won't allow you to add data that doesn't match the column's declared data type. |
||||
@ -0,0 +1,53 @@ |
||||
# UPDATE |
||||
|
||||
The `UPDATE` command in SQL is used to modify the existing records in a table. This command is useful when you need to update existing data within a database. |
||||
|
||||
Here are important points to remember before updating records in SQL: |
||||
|
||||
- The `WHERE` clause in the `UPDATE` statement specifies which records to modify. If you omit the `WHERE` clause, all records in the table will be updated! |
||||
|
||||
- Be careful when updating records in SQL. If you inadvertently run an `UPDATE` statement without a `WHERE` clause, you will rewrite all the data in the table. |
||||
|
||||
## SQL UPDATE Syntax |
||||
|
||||
Here is a basic syntax of SQL UPDATE command: |
||||
|
||||
```sql |
||||
UPDATE table_name |
||||
SET column1 = value1, column2 = value2...., columnN = valueN |
||||
WHERE [condition]; |
||||
``` |
||||
|
||||
In this syntax: |
||||
|
||||
- `table_name`: Specifies the table where you want to update records. |
||||
- `SET`: This keyword is used to set the column values. |
||||
- `column1, column2... columnN`: These are the columns of the table that you want to change. |
||||
- `value1, value2... valueN`: These are the new values that you want to assign for your columns. |
||||
- `WHERE`: This clause specifies which records need to be updated. It selects records based on one or more conditions. |
||||
|
||||
## SQL UPDATE Example |
||||
|
||||
Let's assume we have the following `Students` table: |
||||
|
||||
| StudentID | FirstName | LastName | Age | |
||||
|-----------|-----------|----------|-----| |
||||
| 1 | John | Doe | 20 | |
||||
| 2 | Jane | Smith | 22 | |
||||
| 3 | Bob | Johnson | 23 | |
||||
|
||||
And we want to update the `Age` of the student with `StudentID` as 2. We can use the `UPDATE` command as follows: |
||||
|
||||
```sql |
||||
UPDATE Students |
||||
SET Age = 23 |
||||
WHERE StudentID = 2; |
||||
``` |
||||
|
||||
After executing the above SQL command, the `Age` of the student with `StudentID` 2 will be updated to 23. |
||||
|
||||
| StudentID | FirstName | LastName | Age | |
||||
|-----------|-----------|----------|-----| |
||||
| 1 | John | Doe | 20 | |
||||
| 2 | Jane | Smith | 23 | |
||||
| 3 | Bob | Johnson | 23 | |
||||
@ -0,0 +1,29 @@ |
||||
# WHERE |
||||
|
||||
SQL provides a WHERE clause that is basically used to filter the records. If the condition specified in the WHERE clause satisfies, then only it returns the specific value from the table. You should use the WHERE clause to filter the records and fetching only the necessary records. |
||||
|
||||
The WHERE clause is not only used in SELECT statement, but it is also used in UPDATE, DELETE statement, etc., which we will learn in subsequent chapters. |
||||
|
||||
An example of its implementation is: |
||||
|
||||
```sql |
||||
SELECT * FROM Students WHERE Age>10; |
||||
``` |
||||
|
||||
In this example, the statement selects all fields from the 'Students' table where the 'Age' field value is greater than 10. |
||||
|
||||
WHERE clause can be combined with AND, OR, and NOT operators. Here's an example: |
||||
|
||||
```sql |
||||
SELECT * FROM Students WHERE Age > 10 AND Gender = 'Female'; |
||||
``` |
||||
|
||||
In this example, the statement selects all fields from 'Students' table where the 'Age' field value is greater than 10 and the 'Gender' is Female. |
||||
|
||||
The syntax generally looks like this: |
||||
|
||||
```sql |
||||
SELECT column1, column2, ... |
||||
FROM table_name |
||||
WHERE condition; |
||||
``` |
||||
@ -0,0 +1,37 @@ |
||||
# DELETE |
||||
|
||||
The DELETE statement is used to delete existing records in a table. This is a straightforward process, but care must be taken because the DELETE statement is destructive and cannot be undone by default. |
||||
|
||||
## Syntax |
||||
|
||||
The basic syntax of a DELETE query with WHERE clause in SQL is as follows: |
||||
```sql |
||||
DELETE FROM table_name [WHERE condition] |
||||
``` |
||||
|
||||
- `table_name`: Specifies the table where you want to delete data. |
||||
- `WHERE condition`: It is optional. You can use the WHERE clause with a DELETE query to delete the selected rows, otherwise all the records would be deleted. |
||||
|
||||
## Examples |
||||
|
||||
1. **DELETE ALL Rows** |
||||
|
||||
Deletes all rows from a table named 'students'. |
||||
```sql |
||||
DELETE FROM students; |
||||
``` |
||||
|
||||
2. **DELETE Specified Rows** |
||||
|
||||
Deletes the student whose student_id is '1001' from the 'students' table. |
||||
```sql |
||||
DELETE FROM students WHERE student_id = '1001'; |
||||
``` |
||||
|
||||
**Caution:** Be very careful when using the DELETE statement. If you omit the WHERE clause, all records will be deleted! |
||||
|
||||
## Multi-table deletions |
||||
|
||||
Some database systems allow for deleting from multiple tables in a single DELETE statement. This is database-specific and beyond the scope of the basic SQL DELETE command. |
||||
|
||||
Remember, always make sure to have a backup and confirm you're deleting the correct data before running a DELETE command, especially in production environments. |
||||
@ -0,0 +1,55 @@ |
||||
# ORDER BY |
||||
|
||||
The `ORDER BY` clause in SQL is used to sort the result-set from a SELECT statement in ascending or descending order. It sorts the records in ascending order by default. If you want to sort the records in descending order, you have to use the `DESC` keyword. |
||||
|
||||
## Syntax for Ascending Order: |
||||
```sql |
||||
SELECT column1, column2, ... |
||||
FROM table_name |
||||
ORDER BY column1, column2, ... ASC; |
||||
``` |
||||
Here, `ASC` is used for ascending order. If you use `ORDER BY` without `ASC` or `DESC`, `ASC` is used by default. |
||||
|
||||
## Syntax for Descending Order: |
||||
```sql |
||||
SELECT column1, column2, ... |
||||
FROM table_name |
||||
ORDER BY column1, column2, ... DESC; |
||||
``` |
||||
Here, `DESC` is used for descending order. |
||||
|
||||
## Usage Example |
||||
|
||||
Consider the following `Customers` table: |
||||
|
||||
| ID | NAME | AGE | ADDRESS | SALARY | |
||||
|----|-------|-----|-----------|--------| |
||||
| 1 | Ramesh| 32 | Ahmedabad | 2000.0 | |
||||
| 2 | Khilan| 25 | Delhi | 1500.0 | |
||||
| 3 | kaushik | 23 | Kota | 2000.0 | |
||||
| 4 | Chaitali | 25 | Mumbai | 6500.0 | |
||||
| 5 | Hardik | 27 | Bhopal | 8500.0 | |
||||
| 6 | Komal | 22 | MP | 4500.0 | |
||||
|
||||
**Example 1 - Ascending Order:** |
||||
|
||||
Sort the table by the `NAME` column in ascending order: |
||||
```sql |
||||
SELECT * FROM Customers |
||||
ORDER BY NAME ASC; |
||||
``` |
||||
**Example 2 - Descending Order:** |
||||
|
||||
Sort the table by the `SALARY` column in descending order: |
||||
```sql |
||||
SELECT * FROM Customers |
||||
ORDER BY SALARY DESC; |
||||
``` |
||||
**Example 3 - Multiple Columns:** |
||||
|
||||
You can also sort by multiple columns. Sort the table by the `AGE` column in ascending order and then `SALARY` in descending order: |
||||
```sql |
||||
SELECT * FROM Customers |
||||
ORDER BY AGE ASC, SALARY DESC; |
||||
``` |
||||
In this instance, the `ORDER BY` clause first sorts the `Customers` table by the `AGE` column and then sorts the sorted result further by the `SALARY` column. |
||||
@ -0,0 +1,68 @@ |
||||
# GROUP BY |
||||
|
||||
"Group By" is a clause in SQL that is used to arrange identical data into groups. This clause comes under the category of Group Functions, alongside the likes of Count, Sum, Average, etc. |
||||
|
||||
The syntax for 'Group by' is: |
||||
|
||||
```sql |
||||
SELECT column1, column2 |
||||
FROM table_name |
||||
GROUP BY column1, column2; |
||||
``` |
||||
|
||||
Here, column1, column2, are the names of the columns based on which we want to group the results. |
||||
|
||||
## Example: |
||||
|
||||
Assume we have a "Sales" table. This table has three columns: ID, Item, and Amount. |
||||
|
||||
```sql |
||||
ID Item Amount |
||||
--- ------ ------ |
||||
1 A 150 |
||||
2 B 200 |
||||
3 A 100 |
||||
4 B 50 |
||||
5 A 200 |
||||
6 A 100 |
||||
7 B 150 |
||||
``` |
||||
|
||||
Execute the following SQL statement... |
||||
|
||||
```sql |
||||
SELECT Item, SUM(Amount) |
||||
FROM Sales |
||||
GROUP BY Item; |
||||
``` |
||||
|
||||
This will concatenate, or "group", all items that are the same into one row, applying the SUM() function on their respective Amounts. The output will then be: |
||||
|
||||
```sql |
||||
Item SUM(Amount) |
||||
------ ---------- |
||||
A 550 |
||||
B 400 |
||||
``` |
||||
|
||||
## Group By with Having Clause |
||||
|
||||
The Group By clause can also be used with the Having keyword. The Having keyword allows you to filter the results of the group function. |
||||
|
||||
For example: |
||||
|
||||
```sql |
||||
SELECT Item, SUM(Amount) |
||||
FROM Sales |
||||
GROUP BY Item |
||||
HAVING SUM(Amount) > 150; |
||||
``` |
||||
|
||||
This will return all grouped items where the total amount is more than 150. Hence, the result will be: |
||||
|
||||
```sql |
||||
Item SUM(Amount) |
||||
------ ---------- |
||||
A 550 |
||||
B 400 |
||||
``` |
||||
@ -0,0 +1,44 @@ |
||||
# HAVING |
||||
|
||||
`HAVING` is a clause in SQL that allows you to filter result sets in a `GROUP BY` clause. It is used to mention conditions on the groups being selected. In other words, `HAVING` is mainly used with the `GROUP BY` clause to filter the results that a `GROUP BY` returns. |
||||
|
||||
It’s similar to a `WHERE` clause, but operates on the results of a grouping. The `WHERE` clause places conditions on the selected columns, whereas the `HAVING` clause places conditions on groups created by the `GROUP BY` clause. |
||||
|
||||
## Syntax |
||||
|
||||
The basic syntax is as follows: |
||||
```sql |
||||
SELECT column_name, function(column_name) |
||||
FROM table_name |
||||
WHERE condition |
||||
GROUP BY column_name |
||||
HAVING function(column_name) condition value; |
||||
``` |
||||
|
||||
## Example |
||||
|
||||
Suppose we have a `Sales` table with the following data: |
||||
|
||||
| SaleID | Product | Quantity | |
||||
|--------|---------|----------| |
||||
| 1 | A | 30 | |
||||
| 2 | B | 20 | |
||||
| 3 | A | 100 | |
||||
| 4 | B | 50 | |
||||
| 5 | C | 60 | |
||||
| 6 | A | 70 | |
||||
|
||||
And we want to find products which have total quantity sold more than 100. We can use the `HAVING` clause as follows: |
||||
|
||||
```sql |
||||
SELECT Product, SUM(Quantity) as TotalQuantity |
||||
FROM Sales |
||||
GROUP BY Product |
||||
HAVING TotalQuantity > 100; |
||||
``` |
||||
|
||||
In this query, |
||||
|
||||
- `GROUP BY Product` would group the sales figures by Product. |
||||
- `SUM(Quantity)` would calculate total quantity sold for each product. |
||||
- `HAVING TotalQuantity > 100` would filter out the groups which have total quantity sold less than or equal to 100.- |
||||
@ -0,0 +1,50 @@ |
||||
# JOINs |
||||
|
||||
SQL Joins are used to retrieve data from two or more data tables, based on a related column between them. The key types of JOINs include: |
||||
|
||||
1. INNER JOIN: This type of join returns records with matching values in both tables. |
||||
|
||||
```sql |
||||
SELECT table1.column1, table2.column2... |
||||
FROM table1 |
||||
INNER JOIN table2 |
||||
ON table1.matching_column = table2.matching_column; |
||||
``` |
||||
2. LEFT (OUTER) JOIN: Returns all records from the left table, and matched records from the right table. |
||||
|
||||
```sql |
||||
SELECT table1.column1, table2.column2... |
||||
FROM table1 |
||||
LEFT JOIN table2 |
||||
ON table1.matching_column = table2.matching_column; |
||||
``` |
||||
3. RIGHT (OUTER) JOIN: Returns all records from the right table, and matched records from the left table. |
||||
|
||||
```sql |
||||
SELECT table1.column1, table2.column2... |
||||
FROM table1 |
||||
RIGHT JOIN table2 |
||||
ON table1.matching_column = table2.matching_column; |
||||
``` |
||||
4. FULL (OUTER) JOIN: Returns all records when either a match is found in either left (table1) or right (table2) table records. |
||||
|
||||
```sql |
||||
SELECT table1.column1, table2.column2... |
||||
FROM table1 |
||||
FULL JOIN table2 |
||||
ON table1.matching_column = table2.matching_column; |
||||
``` |
||||
5. SELF JOIN: A self join is a join in which a table is joined with itself. |
||||
|
||||
```sql |
||||
SELECT a.column_name, b.column_name... |
||||
FROM table_name AS a, table_name AS b |
||||
WHERE condition; |
||||
``` |
||||
6. CARTESIAN JOIN: If WHERE clause is omitted, the join operation produces a Cartesian product of the tables involved in the join. The size of a Cartesian product result set is the number of rows in the first table multiplied by the number of rows in the second table. |
||||
|
||||
```sql |
||||
SELECT table1.column1, table2.column2... |
||||
FROM table1, table2; |
||||
``` |
||||
Each type of JOIN allows for the retrieval of data in different situations, making them flexible and versatile for different SQL queries. |
||||
@ -0,0 +1,41 @@ |
||||
# Data Manipulation Language (DML) |
||||
|
||||
*DML* is a subcategory of `SQL` which stands for _Data Manipulation Language_. The purpose of DML is to insert, retrieve, update and delete data from the database. With this, we can perform operations on existing records. |
||||
|
||||
DML contains four commands which are: |
||||
|
||||
1. **INSERT INTO** - This command is used to insert new rows (records) into a table. |
||||
|
||||
Example: |
||||
|
||||
```sql |
||||
INSERT INTO table_name ( column1, column2, column3, ... ) |
||||
VALUES ( value1, value2, value3, ... ) |
||||
``` |
||||
|
||||
2. **SELECT** - This command is used to select data from a database. The data returned is stored in a result table, called the result-set. |
||||
|
||||
Example: |
||||
|
||||
```sql |
||||
SELECT column1, column2, ... |
||||
FROM table_name |
||||
``` |
||||
|
||||
3. **UPDATE** - This command is used to modify the existing rows in a table. |
||||
|
||||
Example: |
||||
|
||||
```sql |
||||
UPDATE table_name |
||||
SET column1 = value1, column2 = value2, ... |
||||
WHERE condition; |
||||
``` |
||||
|
||||
4. **DELETE FROM** - This command is used to delete existing rows (records) from a table. |
||||
|
||||
Example: |
||||
|
||||
```sql |
||||
DELETE FROM table_name WHERE condition; |
||||
``` |
||||
@ -0,0 +1,73 @@ |
||||
# SELECT |
||||
|
||||
`SELECT` is one of the most widely used commands in SQL. This command is used to select data from a database. The data returned is stored in a results table, also called the result-set. |
||||
|
||||
## Syntax |
||||
|
||||
The simplest way to use the `SELECT` statement is to return all columns from a table. This can be done with the following syntax: |
||||
|
||||
```sql |
||||
SELECT * FROM table_name; |
||||
``` |
||||
|
||||
This will return all fields (columns) of all records (rows) from the table. |
||||
|
||||
If you want to select just certain columns, you can specify them by name, separated by commas: |
||||
|
||||
```sql |
||||
SELECT column_name1, column_name2 FROM table_name; |
||||
``` |
||||
|
||||
## SELECT DISTINCT |
||||
|
||||
The `SELECT DISTINCT` statement is used to return only unique values in the output. It can be used to eliminate duplicate values in the returned data. |
||||
|
||||
```sql |
||||
SELECT DISTINCT column_name FROM table_name; |
||||
``` |
||||
|
||||
## WHERE Clause |
||||
|
||||
The `WHERE` clause is used to filter records. The `WHERE` clause is used to extract only those records that fulfill a specified condition. |
||||
|
||||
```sql |
||||
SELECT column_name FROM table_name WHERE condition; |
||||
``` |
||||
|
||||
## ORDER BY |
||||
|
||||
The `ORDER BY` keyword is used to sort the result-set in ascending or descending order. The `ORDER BY` keyword sorts the records in ascending order by default. If you want to sort the records in descending order, you can use the `DESC` keyword. |
||||
|
||||
```sql |
||||
SELECT column_name FROM table_name ORDER BY column_name ASC|DESC; |
||||
``` |
||||
|
||||
## Aggregate Functions |
||||
|
||||
Aggregate functions in SQL are functions where the values of multiple rows are grouped together to form a single value of more significant meaning, such as a list, a set, or a sum. Some examples include `SUM()`, `COUNT()`, `MIN()`, `MAX()`, and `AVG()`. |
||||
|
||||
```sql |
||||
SELECT COUNT(column_name) FROM table_name WHERE condition; |
||||
SELECT AVG(column_name) FROM table_name WHERE condition; |
||||
SELECT SUM(column_name) FROM table_name WHERE condition; |
||||
SELECT MIN(column_name) FROM table_name WHERE condition; |
||||
SELECT MAX(column_name) FROM table_name WHERE condition; |
||||
``` |
||||
|
||||
## GROUP BY |
||||
|
||||
The `GROUP BY` statement is often used with aggregate functions (`COUNT`, `MAX`, `MIN`, `SUM`, `AVG`) to group the result-set by one or more columns. |
||||
|
||||
```sql |
||||
SELECT column_name1, COUNT(column_name2) FROM table_name WHERE condition GROUP BY column_name1 ORDER BY COUNT(column_name2) DESC; |
||||
``` |
||||
|
||||
## HAVING Clause |
||||
|
||||
The `HAVING` clause was added to SQL because the `WHERE` keyword could not be used with aggregate functions. It works like the WHERE clause but on grouped records. |
||||
|
||||
```sql |
||||
SELECT column_name, COUNT(column_name) FROM table_name GROUP BY column_name HAVING COUNT(column_name) > value; |
||||
``` |
||||
|
||||
The above are the most common uses of the `SELECT` keyword in SQL. There are other keywords and functions you can use to manipulate the data as well. These will give you a good start on using `SELECT` in your SQL queries. |
||||
@ -0,0 +1,57 @@ |
||||
# GROUP BY |
||||
|
||||
**Group By** is an SQL clause that arranges identical data into groups. It is often used with aggregate functions (COUNT, MAX, MIN, SUM, AVG) to group the result-set by one or multiple columns. |
||||
|
||||
## Syntax: |
||||
|
||||
```sql |
||||
SELECT column1, column2, ..., aggregate_function(column_name) |
||||
FROM table_name |
||||
WHERE condition |
||||
GROUP BY column1, column2, ...; |
||||
``` |
||||
|
||||
## Explanation: |
||||
|
||||
- **column1, column2**, these columns are not under the aggregate function or any operation. They will be used to group the data. |
||||
- **aggregate_function(column_name)**, Aggregate functions will apply on the group of the column_name specified, not individual rows. |
||||
- The **WHERE** clause is optional. It adds conditions to select which rows will be grouped. |
||||
|
||||
## Examples: |
||||
|
||||
Here's an example of the **Group By** clause in action. Given is a table **Sales**: |
||||
|
||||
| order_id | product_id | qty | |
||||
|----------|------------|-----| |
||||
| 1 | 1001 | 20 | |
||||
| 2 | 1002 | 10 | |
||||
| 3 | 1003 | 50 | |
||||
| 4 | 1001 | 10 | |
||||
| 5 | 1002 | 20 | |
||||
| 6 | 1003 | 50 | |
||||
|
||||
## Example 1: |
||||
```sql |
||||
SELECT product_id, SUM(qty) |
||||
FROM SALES |
||||
GROUP BY product_id; |
||||
``` |
||||
|
||||
The result will be: |
||||
|
||||
|product_id | SUM(qty) |
||||
|-----------|----------| |
||||
| 1001 | 30 | |
||||
| 1002 | 30 | |
||||
| 1003 | 100 | |
||||
|
||||
## Example 2: |
||||
|
||||
You can perform group by operation on multiple columns. In the below example, 'product_id' and 'order_id' are used to group the data. |
||||
```sql |
||||
SELECT product_id, order_id, SUM(qty) |
||||
FROM SALES |
||||
GROUP BY product_id, order_id; |
||||
``` |
||||
|
||||
**Group By** clause can be used with **HAVING** clause to add a condition on grouped data. |
||||
@ -0,0 +1,58 @@ |
||||
# SUM |
||||
|
||||
The `SUM()` function in SQL is used to calculate the sum of a column. This function allows you to add up a column of numbers in an SQL table. |
||||
|
||||
The syntax for SUM is as follows: |
||||
|
||||
```sql |
||||
SELECT SUM(column_name) FROM table_name; |
||||
``` |
||||
|
||||
Where `column_name` is the name of the column you want to calculate the sum of, and `table_name` is the name of the table where the column is. |
||||
|
||||
For example, consider the following `ORDER` table: |
||||
|
||||
``` |
||||
| OrderID | Company | Quantity | |
||||
|-------------|-----------|----------| |
||||
| 1 | A | 30 | |
||||
| 2 | B | 15 | |
||||
| 3 | A | 20 | |
||||
``` |
||||
|
||||
If you want to find the total quantity, you can use `SUM()`: |
||||
|
||||
```sql |
||||
SELECT SUM(Quantity) AS TotalQuantity FROM Order; |
||||
``` |
||||
|
||||
Output will be: |
||||
|
||||
``` |
||||
| TotalQuantity | |
||||
|----------------| |
||||
| 65 | |
||||
``` |
||||
|
||||
**Note:** The `SUM()` function skips NULL values. |
||||
|
||||
One of the common use cases of `SUM()` function is in conjunction with `GROUP BY` to get the sum for each group of rows. |
||||
|
||||
Example: |
||||
|
||||
```sql |
||||
SELECT Company, SUM(Quantity) AS TotalQuantity |
||||
FROM Order |
||||
GROUP BY Company; |
||||
``` |
||||
|
||||
This will give us the sum of `Quantity` for each `Company` in the `Order` table. |
||||
|
||||
``` |
||||
| Company | TotalQuantity | |
||||
|-----------|----------------| |
||||
| A | 50 | |
||||
| B | 15 | |
||||
``` |
||||
|
||||
Notably, in all databases, including MySQL, PostgreSQL, and SQLite, the `SUM()` function operates the same way. |
||||
@ -0,0 +1,29 @@ |
||||
# COUNT |
||||
|
||||
`COUNT` is a SQL function that returns the number of rows that match a specified criteria. Essentially, `COUNT` function is used when you need to know the count of a record in a certain table's column. |
||||
|
||||
There are two types of count function; `COUNT(*)` and `COUNT(column)`. |
||||
|
||||
- `COUNT(*)` counts all the rows in the target table whether columns contain null values or not. |
||||
|
||||
```sql |
||||
SELECT COUNT(*) FROM table_name; |
||||
``` |
||||
|
||||
- `COUNT(column)` counts the rows in the column of a table excluding null. |
||||
|
||||
```sql |
||||
SELECT COUNT(column_name) FROM table_name; |
||||
``` |
||||
|
||||
You may also use `COUNT()` in conjunction with `GROUP BY` to return the count of rows within each group. |
||||
|
||||
A typical example would be: |
||||
|
||||
```sql |
||||
SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name; |
||||
``` |
||||
|
||||
Here, `column_name` is the name of the column based on which the rows will be grouped. This query will return the count of rows in each group of `column_name`. |
||||
|
||||
By understanding how to use the `COUNT()` function, you can extract more meaningful data from your tables, and perform analytics and generate reports based on the counts of certain attributes in your database. |
||||
@ -0,0 +1,51 @@ |
||||
# HAVING |
||||
|
||||
The `HAVING` clause is used in combination with the `GROUP BY` clause to filter the results of `GROUP BY`. It is used to mention conditions on the group functions, like `SUM`, `COUNT`, `AVG`, `MAX` or `MIN`. |
||||
|
||||
It's important to note that where `WHERE` clause introduces conditions on individual rows, `HAVING` introduces conditions on groups created by the `GROUP BY` clause. |
||||
|
||||
Also note, `HAVING` applies to summarized group records, whereas `WHERE` applies to individual records. |
||||
|
||||
Syntax: |
||||
|
||||
```sql |
||||
SELECT column_name(s) |
||||
FROM table_name |
||||
WHERE condition |
||||
GROUP BY column_name(s) |
||||
HAVING condition |
||||
ORDER BY column_name(s); |
||||
``` |
||||
|
||||
## Example |
||||
|
||||
Consider this "Orders" table: |
||||
|
||||
| OrderID | Customer | Amount | |
||||
|---------|----------|--------| |
||||
| 1 | John | 1000 | |
||||
| 2 | Mary | 1500 | |
||||
| 3 | John | 2000 | |
||||
| 4 | Jane | 1000 | |
||||
| 5 | Mary | 2000 | |
||||
| 6 | John | 3000 | |
||||
| 7 | Jane | 2000 | |
||||
| 8 | Mary | 2500 | |
||||
|
||||
For instance, if you wanted to find customers who have spent more than $3000 in total, you might use the `HAVING` clause as follows: |
||||
|
||||
```sql |
||||
SELECT Customer, SUM(Amount) |
||||
FROM Orders |
||||
GROUP BY Customer |
||||
HAVING SUM(Amount) > 3000; |
||||
``` |
||||
|
||||
As a result, the query returns: |
||||
|
||||
| Customer | SUM(Amount) | |
||||
|----------|-------------| |
||||
| John | 6000 | |
||||
| Mary | 6000 | |
||||
|
||||
In this case, the `HAVING` clause filters out all Customers with a total `Amount` less than $3000. Only John and Mary have the total sum of `Amount` more than or equal to $3000. Thus, only these records satisfy the `HAVING` clause and are included in the result. |
||||
@ -0,0 +1,40 @@ |
||||
# AVG |
||||
|
||||
The `AVG()` function in SQL is an aggregate function that returns the average value of a numeric column. It calculates the sum of values in a column and then divides it by the count of those values. |
||||
|
||||
Syntax: |
||||
``` |
||||
SELECT AVG(column_name) |
||||
FROM table_name; |
||||
``` |
||||
This statement will return the average value of the specified column. |
||||
|
||||
## Example Usage of AVG: |
||||
|
||||
Consider the following table `Orders`: |
||||
|
||||
| OrderID | CustomerID | Quantity | |
||||
|---------|------------|----------| |
||||
| 1 | A | 30 | |
||||
| 2 | A | 40 | |
||||
| 3 | B | 20 | |
||||
| 4 | B | 60 | |
||||
| 5 | C | 50 | |
||||
| 6 | C | 10 | |
||||
|
||||
Let's calculate the average quantity in the `Orders` table: |
||||
```sql |
||||
SELECT AVG(Quantity) AS AvgQuantity |
||||
FROM Orders; |
||||
``` |
||||
The result is 35. This value is the average of all `Quantity` values in the table. |
||||
|
||||
It's also possible to group the average function by one or more columns. For example, to find the average quantity of order per customer, we can write: |
||||
```sql |
||||
SELECT CustomerID, AVG(Quantity) as AvgQuantity |
||||
FROM Orders |
||||
GROUP BY CustomerID; |
||||
``` |
||||
It will calculate the average quantity for each customer and display the result along with the associated customer's ID. |
||||
|
||||
> Note: The `AVG()` function works only with numeric data types (`INT`, `FLOAT`, `DECIMAL`, etc.). It will return an error if used with non-numeric data types. |
||||
@ -0,0 +1,57 @@ |
||||
# MIN |
||||
|
||||
`MIN` is an SQL aggregate function used to return the smallest value in a selected column. It is useful in querying tables where users want to identify the smallest or least available value in datasets. `MIN` ignores any null values in the dataset. |
||||
|
||||
Syntax: |
||||
|
||||
```sql |
||||
SELECT MIN(column_name) |
||||
FROM table_name |
||||
WHERE condition; |
||||
``` |
||||
|
||||
In the case where `column_name` belongs to a numeric data type (Integers, Float, etc.), `MIN` returns the smallest numeric value in the column. |
||||
|
||||
If `column_name` belongs to datetime types (Date, Time, etc.), `MIN` returns the earliest date or time. |
||||
|
||||
If `column_name` belongs to string types (Char, Text, etc.), `MIN` returns the lowest value in lexicographic order (similar to alphabetic order). |
||||
|
||||
## Examples: |
||||
|
||||
Consider a table, named `Orders`, with the following layout: |
||||
|
||||
| OrderID | CustomerID | OrderDate | |
||||
|---------|-------------|------------| |
||||
| 1 | C01 | 2020-10-10 | |
||||
| 2 | C02 | 2020-09-05 | |
||||
| 3 | C01 | 2020-08-21 | |
||||
|
||||
1. To find the earliest order date in the `Orders` table, the `MIN` function is used in the following way: |
||||
|
||||
```sql |
||||
SELECT MIN(OrderDate) AS EarliestOrder |
||||
FROM Orders; |
||||
``` |
||||
|
||||
The result of this query will be `2020-08-21`. |
||||
|
||||
2. Suppose we have a Prices table with items and their prices. To find the lowest price, use: |
||||
|
||||
```sql |
||||
SELECT MIN(price) AS LowestPrice |
||||
FROM Prices; |
||||
``` |
||||
|
||||
This query will return the smallest value in the price column. |
||||
|
||||
One important usage is when it is used along with the `GROUP BY` clause to find the minimum value in each group. |
||||
|
||||
Example, to find the earliest order date for each customer: |
||||
|
||||
```sql |
||||
SELECT CustomerID, MIN(OrderDate) AS EarliestOrder |
||||
FROM Orders |
||||
GROUP BY CustomerID; |
||||
``` |
||||
|
||||
This query will return the earliest order date for each customer. |
||||
@ -0,0 +1,37 @@ |
||||
# MAX |
||||
|
||||
The `MAX()` function in SQL is used to return the maximum value of an expression in a SELECT statement. |
||||
|
||||
It can be used for numeric, character, and datetime column data types. If there are null values, then they are not considered for comparison. |
||||
|
||||
## Syntax |
||||
|
||||
```sql |
||||
SELECT MAX(column_name) |
||||
FROM table_name |
||||
WHERE condition; |
||||
``` |
||||
|
||||
In this syntax, the `column_name` argument is the column in the `table_name` that you wish to find the maximum value of. |
||||
|
||||
## Example |
||||
|
||||
Consider the following Employee table: |
||||
|
||||
| ID | NAME | SALARY | |
||||
|----|----------|--------| |
||||
| 1 | John | 1000 | |
||||
| 2 | Robert | 2000 | |
||||
| 3 | Jim | 3000 | |
||||
| 4 | Jessica | 2500 | |
||||
|
||||
To find the highest salary amongst all the employees, you would use the `MAX()` function as follows: |
||||
|
||||
```sql |
||||
SELECT MAX(SALARY) AS "Highest Salary" |
||||
FROM Employee; |
||||
``` |
||||
|
||||
The above SQL returns `3000` as it’s the highest salary in the Employee table. |
||||
|
||||
Warning: SQL `MAX()` function will only return a single row as a result. If multiple rows hold the highest value and if you want to get all these rows, you should not use `MAX()`. A better option would be sorting the column and then `LIMIT` the result just to the first row. |
||||
@ -0,0 +1,80 @@ |
||||
# Aggregate Queries |
||||
|
||||
SQL aggregate functions are inbuilt functions that are used to perform some calculation on the data and return a single value. This is why they form the basis for "aggregate queries". These functions operate on a set of rows and return a single summarized result. |
||||
|
||||
## Common Aggregate Functions |
||||
|
||||
**1. COUNT()** |
||||
|
||||
Counts the number of rows. |
||||
``` |
||||
SELECT COUNT(column_name) |
||||
FROM table_name |
||||
WHERE condition; |
||||
``` |
||||
|
||||
**2. SUM()** |
||||
|
||||
Returns the sum of a numeric column. |
||||
|
||||
``` |
||||
SELECT SUM(column_name) |
||||
FROM table_name |
||||
WHERE condition; |
||||
``` |
||||
|
||||
**3. AVG()** |
||||
|
||||
Returns the average value of a numeric column. |
||||
``` |
||||
SELECT AVG(column_name) |
||||
FROM table_name |
||||
WHERE condition; |
||||
``` |
||||
|
||||
**4. MIN()** |
||||
|
||||
Returns the smallest value of the selected column. |
||||
``` |
||||
SELECT MIN(column_name) |
||||
FROM table_name |
||||
WHERE condition; |
||||
``` |
||||
|
||||
**5. MAX()** |
||||
|
||||
Returns the largest value of the selected column. |
||||
``` |
||||
SELECT MAX(column_name) |
||||
FROM table_name |
||||
WHERE condition; |
||||
``` |
||||
|
||||
These functions ignore NULL values. |
||||
|
||||
## GROUP BY and HAVING Clauses |
||||
|
||||
To separate the results into groups of accumulated data, you can use the GROUP BY clause. |
||||
|
||||
``` |
||||
SELECT column1, aggregate_function(column2) |
||||
FROM table |
||||
GROUP BY column1; |
||||
``` |
||||
|
||||
"A group" is represented by ROW(s) that have the same value in the specific column(s). The GROUP BY clause can be used in a SELECT statement to collect data across multiple records and group by some columns. |
||||
|
||||
The HAVING clause is used with the GROUP BY clause, it applies to summarized group records, unlike the 'where' clause. It was added to SQL because the WHERE keyword could not be used with aggregate functions. |
||||
|
||||
```sql |
||||
SELECT column1, aggregate_function(column2) |
||||
FROM table |
||||
GROUP BY column1 |
||||
HAVING conditions; |
||||
``` |
||||
|
||||
## Conclusion |
||||
|
||||
Aggregate queries are simply a way of summarizing information in your database. Although they are a powerful tool, they can become complex very quickly, especially if you start nesting them together or combining multiple aggregate functions in a single query. |
||||
|
||||
> Note: The real power of aggregate functions comes when you combine them with the WHERE or HAVING clause, allowing you to filter the data that you are summarizing. |
||||
@ -0,0 +1,52 @@ |
||||
# Primary Key |
||||
|
||||
A primary key is a special relational database table field (or combination of fields) designated to uniquely identify all table records. |
||||
|
||||
A primary key's main features are: |
||||
|
||||
- It must contain a unique value for each row of data. |
||||
- It cannot contain null values. |
||||
|
||||
## Usage of Primary Key |
||||
|
||||
You define a primary key for a table using the `PRIMARY KEY` constraint. A table can have only one primary key. You can define a primary key in SQL when you create or modify a table. |
||||
|
||||
## Create Table With Primary Key |
||||
|
||||
In SQL, you can create a table with a primary key by using `CREATE TABLE` syntax. |
||||
|
||||
```sql |
||||
CREATE TABLE Employees ( |
||||
ID INT PRIMARY KEY, |
||||
NAME TEXT, |
||||
AGE INT, |
||||
ADDRESS CHAR(50) |
||||
); |
||||
``` |
||||
|
||||
In this example, `ID` is the primary key which must consist of unique values and can't be null. |
||||
|
||||
## Modify Table to Add Primary Key |
||||
|
||||
If you want to add a primary key to an existing table, you can use `ALTER TABLE` syntax. |
||||
|
||||
```sql |
||||
ALTER TABLE Employees |
||||
ADD PRIMARY KEY (ID); |
||||
``` |
||||
|
||||
This will add a primary key to `ID` column in the `Employees` table. |
||||
|
||||
## Composite Primary Key |
||||
|
||||
We can also use multiple columns to define a primary key. Such key is known as composite key. |
||||
|
||||
```sql |
||||
CREATE TABLE Customers ( |
||||
CustomerID INT, |
||||
StoreID INT, |
||||
CONSTRAINT pk_CustomerID_StoreID PRIMARY KEY (CustomerID,StoreID) |
||||
); |
||||
``` |
||||
|
||||
In this case, each combination of `CustomerID` and `StoreID` must be unique across the whole table. |
||||
@ -0,0 +1,37 @@ |
||||
# Foreign Key |
||||
|
||||
A foreign key is a key used to link two tables together. It is a field (or collection of fields) in one table that refers to the primary key in another table. The table with the foreign key is called the child table, and the one with the primary key is called the referenced or parent table. |
||||
|
||||
## Basic Syntax |
||||
|
||||
The SQL used to add a foreign key constraint is: |
||||
|
||||
```sql |
||||
ALTER TABLE child_table |
||||
ADD FOREIGN KEY (fk_column) |
||||
REFERENCES parent_table (parent_key_column) |
||||
``` |
||||
|
||||
Where: |
||||
- `child_table` is the table where you want to add the foreign key |
||||
- `fk_column` is the field in the child table that you want to use as foreign key |
||||
- `parent_table` is the table being referenced by the foreign key |
||||
- `parent_key_column` is the column in `parent_table` that `fk_column` points to |
||||
|
||||
## Example |
||||
|
||||
Suppose we have two tables, `Orders` and `Customers` where `Orders` table has a column `customer_id` that should point to a Customer. If `Customers` has a `customer_id` column as the primary key then you can create a foreign key as follows |
||||
|
||||
```sql |
||||
ALTER TABLE Orders |
||||
ADD FOREIGN KEY (customer_id) |
||||
REFERENCES Customers (customer_id); |
||||
``` |
||||
|
||||
This means that for every row in `Orders`, the `customer_id` value must match a value in the `Customers` table, ensuring data integrity. |
||||
|
||||
## Note |
||||
|
||||
Please note that MySQL requires you to have the foreign key columns be indexed for performance reasons. If they aren't indexed already, the `FOREIGN KEY` constraint will implicitly index them for you. Also, a significant thing to note is, InnoDB does not support the 'foreign key check' in CREATE TABLE statements, instead, you must use ALTER TABLE after the table has been created. |
||||
|
||||
Not all database systems support all types of keys, and different systems support different syntax for them. The examples above are in SQL syntax, which is supported by most databases. |
||||
@ -0,0 +1,54 @@ |
||||
# Unique |
||||
|
||||
The `UNIQUE` constraint ensures that all values in a column are different; that is, each value in the column should occur only once. |
||||
|
||||
Both the `UNIQUE` and `PRIMARY KEY` constraints provide a guarantee for uniqueness for a column or set of columns. However, a primary key can contain only `NULL`, and each table can have only one primary key. On the other hand, a `UNIQUE` constraint allows for one `NULL` value, and a table can have multiple `UNIQUE` constraints. |
||||
|
||||
## Syntax |
||||
```sql |
||||
CREATE TABLE table_name ( |
||||
column1 data_type UNIQUE, |
||||
column2 data_type, |
||||
column3 data_type, |
||||
.... |
||||
); |
||||
``` |
||||
|
||||
Here, `UNIQUE` is the constraint's name, whereas `column1` and `data_type` refer to the column and data type for which we're setting the constraint, respectively. |
||||
|
||||
## Example |
||||
|
||||
Suppose, for instance, we are creating a table named "Employees". We want the "Email" column to contain only unique values to avoid any duplication in email addresses. |
||||
|
||||
Here's how we can impose a `UNIQUE` constraint on the "Email" column: |
||||
|
||||
```sql |
||||
CREATE TABLE Employees ( |
||||
ID int NOT NULL, |
||||
Name varchar (255) NOT NULL, |
||||
Email varchar (255) UNIQUE |
||||
); |
||||
``` |
||||
|
||||
In this SQL command, we are telling the SQL server that the "Email" column cannot have the same value in two or more rows. |
||||
|
||||
## Adding a Unique Constraint to an Existing Table |
||||
|
||||
To add a `UNIQUE` constraint to an existing table, you would use the `ALTER TABLE` command. Here is the syntax: |
||||
|
||||
```sql |
||||
ALTER TABLE table_name |
||||
ADD UNIQUE (column1, column2, ...); |
||||
``` |
||||
Here, `table_name` is the name of the table on which we're defining the constraint, and `column1`, `column2`, etc., are the names of the columns included in the constraint. |
||||
|
||||
## Dropping a Unique Constraint |
||||
|
||||
The `ALTER TABLE` command is also used to drop a `UNIQUE` constraint. The syntax to drop a `UNIQUE` constraint is: |
||||
|
||||
```sql |
||||
ALTER TABLE table_name |
||||
DROP CONSTRAINT constraint_name; |
||||
``` |
||||
|
||||
Here, `constraint_name` is the name of the `UNIQUE` constraint that you want to drop. |
||||
@ -0,0 +1,40 @@ |
||||
# NOT NULL |
||||
|
||||
The `NOT NULL` constraint in SQL ensures that a column cannot have a NULL value. Thus, every row/record must contain a value for that column. It is a way to enforce certain fields to be mandatory while inserting records or updating records in a table. |
||||
|
||||
For instance, if you're designing a table for employee data, you might want to ensure that the employee's `id` and `name` are always provided. In this case, you'd use the `NOT NULL` constraint. |
||||
|
||||
## Creating a table with NOT NULL |
||||
|
||||
Here's an example of how you would define a `NOT NULL` constraint when creating a table: |
||||
|
||||
```sql |
||||
CREATE TABLE Employees ( |
||||
ID int NOT NULL, |
||||
Name varchar(255) NOT NULL, |
||||
Age int, |
||||
Address varchar(255) |
||||
); |
||||
``` |
||||
|
||||
In this example, the `ID` and `Name` fields are mandatory for each record. |
||||
|
||||
## Adding NOT NULL to an existing table |
||||
|
||||
You can also add a `NOT NULL` constraint to an existing table using the `ALTER TABLE` statement. However, make sure there are no NULL values in the column before adding the `NOT NULL` constraint. |
||||
|
||||
Here's an example: |
||||
|
||||
```sql |
||||
ALTER TABLE Employees |
||||
MODIFY Address varchar(255) NOT NULL; |
||||
``` |
||||
|
||||
This command will modify the table `Employees` and set the `Address` column to be `NOT NULL`. |
||||
|
||||
**Note:** In some SQL systems like PostgreSQL, you use the `ALTER TABLE` command followed by `SET NOT NULL`. |
||||
|
||||
--- |
||||
|
||||
Be aware that if you try to insert a record without a value for a `NOT NULL` column, the database will return an error and the operation will fail. |
||||
Ensure data compatibility before setting the `NOT NULL` constraint. |
||||
@ -0,0 +1,64 @@ |
||||
# CHECK |
||||
|
||||
In SQL, `CHECK` is a constraint that limits the value range that can be placed in a column. It enforces domain integrity by limiting the values in a column to meet a certain condition. |
||||
|
||||
`CHECK` constraint can be used in a column definition when you create or modify a table. |
||||
|
||||
## Syntax |
||||
|
||||
To use the `CHECK` constraint, you can follow this syntax: |
||||
|
||||
```sql |
||||
CREATE TABLE table_name ( |
||||
column1 datatype CONSTRAINT constraint_name CHECK (condition), |
||||
column2 datatype, |
||||
... |
||||
); |
||||
``` |
||||
|
||||
If you need to apply the `CHECK` constraint on multiple columns, use the following syntax: |
||||
|
||||
```sql |
||||
CREATE TABLE table_name ( |
||||
column1 datatype, |
||||
column2 datatype, |
||||
..., |
||||
CONSTRAINT constraint_name CHECK (condition) |
||||
); |
||||
``` |
||||
|
||||
## Examples |
||||
|
||||
Here is an example of applying a `CHECK` constraint on a single column: |
||||
|
||||
```sql |
||||
CREATE TABLE Employees ( |
||||
ID int NOT NULL, |
||||
Age int, |
||||
Salary int CHECK (Salary>0), |
||||
); |
||||
``` |
||||
|
||||
Above SQL statement ensures that the salary of all employees in the Employees table must be more than 0. |
||||
|
||||
Here is an example of applying a `CHECK` constraint on multiple columns: |
||||
|
||||
```sql |
||||
CREATE TABLE Employees ( |
||||
ID int NOT NULL, |
||||
Age int, |
||||
Salary int, |
||||
CONSTRAINT CHK_Person CHECK (Age>=18 AND Salary>=0) |
||||
); |
||||
``` |
||||
|
||||
Above SQL ensures that the persons' age must be greater than or equal to 18, and their salary is more than or equal to 0. |
||||
|
||||
It is also possible to use the `ALTER TABLE` command to add a `CHECK` constraint after the table has been created. |
||||
|
||||
```sql |
||||
ALTER TABLE Employees |
||||
ADD CONSTRAINT CHK_EmployeeAge CHECK (Age >= 21 AND Age <= 60); |
||||
``` |
||||
|
||||
Above SQL ensures that the employees' age must be between 21 and 60. |
||||
@ -0,0 +1,93 @@ |
||||
# Data Constraints |
||||
|
||||
Data constraints in SQL are used to specify rules for the data in a table. Constraints are used to limit the type of data that can go into a table. This ensures the accuracy and reliability of the data in the table. |
||||
|
||||
## Types of SQL Data Constraints |
||||
|
||||
1. **NOT NULL Constraint**: Ensures that a column cannot have a NULL value. |
||||
|
||||
For Example: |
||||
|
||||
```sql |
||||
CREATE TABLE Students ( |
||||
ID int NOT NULL, |
||||
Name varchar(255) NOT NULL, |
||||
Age int |
||||
); |
||||
``` |
||||
|
||||
2. **UNIQUE Constraint**: Ensures that all values in a column are different. |
||||
|
||||
For Example: |
||||
|
||||
```sql |
||||
CREATE TABLE Students ( |
||||
ID int NOT NULL UNIQUE, |
||||
Name varchar(255) NOT NULL, |
||||
Age int |
||||
); |
||||
``` |
||||
|
||||
3. **PRIMARY KEY Constraint**: Uniquely identifies each record in a database table. Primary keys must contain UNIQUE values. Exactly the same as the UNIQUE constraint but there can be many unique constraints in a table, but only one PRIMARY KEY constraint per table. |
||||
|
||||
For Example: |
||||
|
||||
```sql |
||||
CREATE TABLE Students ( |
||||
ID int NOT NULL, |
||||
Name varchar(255) NOT NULL, |
||||
Age int, |
||||
PRIMARY KEY (ID) |
||||
); |
||||
``` |
||||
|
||||
4. **FOREIGN KEY Constraint**: Prevents actions that would destroy links between tables. A FOREIGN KEY is a field (or collection of fields) in one table that refers to the PRIMARY KEY in another table. |
||||
|
||||
For Example: |
||||
|
||||
```sql |
||||
CREATE TABLE Orders ( |
||||
OrderID int NOT NULL, |
||||
OrderNumber int NOT NULL, |
||||
ID int, |
||||
PRIMARY KEY (OrderID), |
||||
FOREIGN KEY (ID) REFERENCES Students(ID) |
||||
); |
||||
``` |
||||
|
||||
5. **CHECK Constraint**: The CHECK constraint ensures that all values in a column satisfies certain conditions. |
||||
|
||||
For Example: |
||||
|
||||
```sql |
||||
CREATE TABLE Students ( |
||||
ID int NOT NULL, |
||||
Name varchar(255) NOT NULL, |
||||
Age int, |
||||
CHECK (Age>=18) |
||||
); |
||||
``` |
||||
|
||||
6. **DEFAULT Constraint**: Provides a default value for a column when none is specified. |
||||
|
||||
For Example: |
||||
|
||||
```sql |
||||
CREATE TABLE Students ( |
||||
ID int NOT NULL, |
||||
Name varchar(255) NOT NULL, |
||||
Age int, |
||||
City varchar(255) DEFAULT 'Unknown' |
||||
); |
||||
``` |
||||
|
||||
7. **INDEX Constraint**: Used to create and retrieve data from the database very quickly. |
||||
|
||||
For Example: |
||||
|
||||
```sql |
||||
CREATE INDEX idx_name |
||||
ON Students (Name); |
||||
``` |
||||
|
||||
Note: Indexes are not a part of the SQL standard and are not supported by all databases. |
||||
@ -0,0 +1,58 @@ |
||||
# INNER JOIN |
||||
|
||||
An `INNER JOIN` in SQL is a type of join that returns the records with matching values in both tables. This operation compares each row of the first table with each row of the second table to find all pairs of rows that satisfy the join predicate. |
||||
|
||||
Few things to consider in case of `INNER JOIN`: |
||||
|
||||
- It is a default join in SQL. If you mention `JOIN` in your query without specifying the type, SQL considers it as an `INNER JOIN`. |
||||
- It returns only the matching rows from both the tables. |
||||
- If there is no match, the returned is an empty result. |
||||
|
||||
## Syntax |
||||
|
||||
Here is the syntax for an SQL `INNER JOIN`: |
||||
|
||||
```sql |
||||
SELECT column_name(s) |
||||
FROM table1 |
||||
INNER JOIN table2 |
||||
ON table1.column_name = table2.column_name; |
||||
``` |
||||
|
||||
The `INNER JOIN` keyword selects records that have matching values in both tables. |
||||
|
||||
## Example |
||||
|
||||
Consider two tables: |
||||
|
||||
**Table1: `Orders`** |
||||
|
||||
|OrderID|CustomerID|OrderAmount| |
||||
|-------|----------|-----------| |
||||
|1 |100 |30 | |
||||
|2 |101 |40 | |
||||
|3 |102 |50 | |
||||
|
||||
**Table2: `Customers`** |
||||
|
||||
|CustomerID|Name |Country | |
||||
|----------|--------|---------| |
||||
|100 |Ana |Germany | |
||||
|101 |Ben |USA | |
||||
|103 |Charlie |Australia| |
||||
|
||||
Now, if you want to select all orders, and any matching customer information: |
||||
|
||||
```sql |
||||
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderAmount |
||||
FROM Orders |
||||
INNER JOIN Customers |
||||
ON Orders.CustomerID = Customers.CustomerID; |
||||
``` |
||||
|
||||
This would produce the following result: |
||||
|
||||
|OrderID|Name|OrderAmount| |
||||
|-------|----|-----------| |
||||
|1 |Ana |30 | |
||||
|2 |Ben |40 | |
||||
@ -0,0 +1,30 @@ |
||||
# LEFT JOIN |
||||
|
||||
The SQL LEFT JOIN combines rows from two or more tables based on a related column between them and returns all rows from the left table (table1) and the matched rows from the right table (table2). If there is no match, the result is `NULL` on the right side. |
||||
|
||||
## Syntax |
||||
``` |
||||
SELECT column_name(s) |
||||
FROM table1 |
||||
LEFT JOIN table2 |
||||
ON table1.column_name = table2.column_name; |
||||
``` |
||||
|
||||
## How SQL LEFT JOIN Works |
||||
|
||||
The `LEFT JOIN` keyword returns all records from the left table (table1), and the matched records from the right table (table2). The result is `NULL` from the right side, if there is no match. |
||||
|
||||
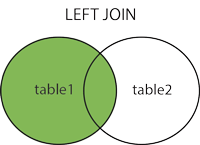 |
||||
|
||||
## SQL LEFT JOIN Example |
||||
|
||||
Let's assume we have two tables: `Orders` and `Customers`. |
||||
|
||||
```sql |
||||
SELECT Orders.OrderID, Customers.CustomerName |
||||
FROM Orders |
||||
LEFT JOIN Customers |
||||
ON Orders.CustomerID = Customers.CustomerID; |
||||
``` |
||||
|
||||
This SQL statement would return all OrderID and the matching CustomerName. If there is no match, the result is `NULL`. |
||||
@ -0,0 +1,63 @@ |
||||
# RIGHT JOIN |
||||
|
||||
The `RIGHT JOIN` keyword returns all records from the right table (table2), and the matched records from the left table (table1). If there is no match, the result is `NULL` on the left side. |
||||
|
||||
## Syntax |
||||
|
||||
Below is the common syntax used for writing a `RIGHT JOIN`: |
||||
|
||||
```sql |
||||
SELECT column_name(s) |
||||
FROM table1 |
||||
RIGHT JOIN table2 |
||||
ON table1.column_name = table2.column_name; |
||||
``` |
||||
|
||||
## Example |
||||
|
||||
Consider two tables: |
||||
|
||||
**Table "Orders":** |
||||
|
||||
| OrderID | CustomerID | OrderDate | |
||||
|--|--|--| |
||||
| 1 | 3 | 2017/11/11 | |
||||
| 2 | 1 | 2017/10/23 | |
||||
| 3 | 2 | 2017/9/15 | |
||||
| 4 | 4 | 2017/9/03 | |
||||
|
||||
**Table "Customers":** |
||||
|
||||
| CustomerID | CustomerName | ContactName | Country | |
||||
|--|--|--|--| |
||||
| 1 | Alfreds Futterkiste | Maria Anders | Germany | |
||||
| 2 | Ana Trujillo Emparedados y helados | Ana Trujillo | Mexico | |
||||
| 3 | Antonio Moreno Taquería | Antonio Moreno | Mexico | |
||||
| 5 | Berglunds snabbköp | Christina Berglund | Sweden | |
||||
|
||||
Now, we want to select all customers and any matching records in orders table. If there is no match, the result is null in order table: |
||||
|
||||
```sql |
||||
SELECT |
||||
Customers.CustomerName, |
||||
Orders.OrderID |
||||
FROM |
||||
Orders |
||||
RIGHT JOIN |
||||
Customers |
||||
ON |
||||
Orders.CustomerID = Customers.CustomerID; |
||||
``` |
||||
|
||||
**Result:** |
||||
|
||||
| CustomerName | OrderID | |
||||
|--|--| |
||||
| Alfreds Futterkiste | 2 | |
||||
| Ana Trujillo Emparedados y helados | 3 | |
||||
| Antonio Moreno Taquería | 1 | |
||||
| Berglunds snabbköp | NULL | |
||||
| Around the Horn | NULL | |
||||
| Bottom-Dollar Markets | NULL | |
||||
|
||||
As you can see, the `RIGHT JOIN` keyword returned all the records from the Customers table and all matched records from the Orders table. For those customers who have no orders (like "Berglunds snabbköp"), the result is `NULL`. |
||||
@ -0,0 +1,63 @@ |
||||
# FULL OUTER JOIN |
||||
|
||||
A `FULL OUTER JOIN` in SQL is a method to combine rows from two or more tables, based on a related column between them. It returns all rows from the left table (`table1`) and from the right table (`table2`). |
||||
|
||||
The `FULL OUTER JOIN` keyword combines the results of both left and right outer joins and returns all (matched or unmatched) rows from the tables on both sides of the join clause. |
||||
|
||||
If there are records in the "Customers" table that do not have matches in the "Orders" table, those will be included. Also, if there are records in the "Orders" table that do not have matches in the "Customers" table, those will be included. |
||||
|
||||
## Syntax |
||||
|
||||
``` |
||||
SELECT column_name(s) |
||||
FROM table1 |
||||
FULL OUTER JOIN table2 |
||||
ON table1.column_name = table2.column_name; |
||||
``` |
||||
|
||||
## Code Example |
||||
|
||||
Consider the following two tables: |
||||
|
||||
**Table1: Customers** |
||||
|
||||
| ID | Name | |
||||
|----|-------| |
||||
| 1 | Tom | |
||||
| 2 | Lucy | |
||||
| 3 | Steve | |
||||
| 4 | Dave | |
||||
|
||||
**Table2: Orders** |
||||
|
||||
| OrderID | CustomerID | Product | |
||||
|---------|------------|----------| |
||||
| 1 | 3 | Apple | |
||||
| 2 | 3 | Banana | |
||||
| 3 | 1 | Orange | |
||||
| 4 | 2 | Mango | |
||||
| 5 | 7 | Blueberry| |
||||
|
||||
A `FULL OUTER JOIN` query would look like this: |
||||
|
||||
``` |
||||
SELECT Customers.Name, Orders.Product |
||||
FROM Customers |
||||
FULL OUTER JOIN Orders |
||||
ON Customers.ID = Orders.CustomerID |
||||
ORDER BY Customers.Name; |
||||
``` |
||||
|
||||
The result-set will look like this: |
||||
|
||||
| Name | Product | |
||||
|-------|----------| |
||||
| Tom | Orange | |
||||
| Lucy | Mango | |
||||
| Steve | Apple | |
||||
| Steve | Banana | |
||||
| NULL | Blueberry| |
||||
| Dave | NULL | |
||||
|
||||
This response includes all customers and all orders. If no matching orders exist for a customer, or if no matching customer exists for an order, the missing side will contain NULL. |
||||
For example, Dave made no orders (his details in the product column are NULL) and the Blueberry order was made by a non-existing customer (the customer's details are NULL in the name column). |
||||
@ -0,0 +1,44 @@ |
||||
# Self Join |
||||
|
||||
A `SELF JOIN` is a standard SQL operation where a table is joined to itself. This might sound counter-intuitive, but it's actually quite useful in scenarios where comparison operations need to be made within a table. Essentially, it is used to combine rows with other rows in the same table when there's a match based on the condition provided. |
||||
|
||||
It's important to note that, since it's a join operation on the same table, alias(es) for table(s) must be used to avoid confusion during the join operation. |
||||
|
||||
## Syntax of a Self Join |
||||
|
||||
Here is the basic syntax for a `SELF JOIN` statement: |
||||
|
||||
```sql |
||||
SELECT a.column_name, b.column_name |
||||
FROM table_name AS a, table_name AS b |
||||
WHERE a.common_field = b.common_field; |
||||
``` |
||||
|
||||
In this query: |
||||
|
||||
- `table_name`: is the name of the table to join to itself. |
||||
- `a` and `b`: are different aliases for the same table. |
||||
- `column_name`: specify the columns that should be returned as a result of the SQL `SELF JOIN` statement. |
||||
- `WHERE a.common_field = b.common_field`: is the condition for the join. |
||||
|
||||
## Example of a Self Join |
||||
|
||||
Let us consider a `EMPLOYEES` table with the following structure: |
||||
|
||||
| EmployeeID | Name | ManagerID | |
||||
|------------|-------|-----------| |
||||
| 1 | Sam | NULL | |
||||
| 2 | Alex | 1 | |
||||
| 3 | John | 1 | |
||||
| 4 | Sophia| 2 | |
||||
| 5 | Emma | 2 | |
||||
|
||||
If you want to find out all the employees and who their manager is, you can do so using a `SELF JOIN`: |
||||
|
||||
```sql |
||||
SELECT a.Name AS Employee, b.Name AS Manager |
||||
FROM EMPLOYEES a, EMPLOYEES b |
||||
WHERE a.ManagerID = b.EmployeeID; |
||||
``` |
||||
|
||||
This query will return the name of each employee along with the name of their respective manager. |
||||
@ -0,0 +1,37 @@ |
||||
# Cross Join |
||||
|
||||
The cross join in SQL is used to combine every row of the first table with every row of the second table. It's also known as the Cartesian product of the two tables. The most important aspect of performing a cross join is that it does not require any condition to join. |
||||
|
||||
The issue with cross join is it returns the Cartesian product of the two tables, which can result in large numbers of rows and heavy resource usage. It's hence critical to use them wisely and only when necessary. |
||||
|
||||
## Syntax |
||||
|
||||
Here's the generic syntax for implementing a CROSS JOIN: |
||||
|
||||
```sql |
||||
SELECT column_name(s) |
||||
FROM table1 |
||||
CROSS JOIN table2; |
||||
``` |
||||
|
||||
You can alternatively use the below syntax to achieve the same result: |
||||
|
||||
```sql |
||||
SELECT column_name(s) |
||||
FROM table1, table2; |
||||
``` |
||||
Both syntax return the Cartesian product of `table1` and `table2`. |
||||
|
||||
## Example of CROSS JOIN |
||||
|
||||
Let's consider two tables, `Employees` and `Departments`, where `Employees` has columns `EmpID, EmpName, DeptID` and `Departments` has columns `DeptID, DeptName`. |
||||
|
||||
A cross join query would look like this: |
||||
|
||||
```sql |
||||
SELECT Employees.EmpName, Departments.DeptName |
||||
FROM Employees |
||||
CROSS JOIN Departments; |
||||
``` |
||||
|
||||
This statement will return a result set which is the combination of each row from `Employees` with each row from `Departments`. |
||||
@ -0,0 +1,62 @@ |
||||
# JOIN Queries |
||||
|
||||
Absolutely, here's a brief summary about SQL JOIN Queries: |
||||
|
||||
# SQL JOIN Queries |
||||
|
||||
JOIN clause is used to combine rows from two or more tables, based on a related column between them. |
||||
|
||||
## INNER JOIN: |
||||
|
||||
Inner join returns records that have matching values in both tables. For example: |
||||
|
||||
```sql |
||||
SELECT Orders.OrderID, Customers.CustomerName |
||||
FROM Orders |
||||
INNER JOIN Customers |
||||
ON Orders.CustomerID = Customers.CustomerID; |
||||
``` |
||||
|
||||
## LEFT (OUTER) JOIN: |
||||
|
||||
Returns all records from the left table, and the matched records from the right table. Also returns NULL if there is no match. Example: |
||||
|
||||
```sql |
||||
SELECT Customers.CustomerName, Orders.OrderID |
||||
FROM Customers |
||||
LEFT JOIN Orders |
||||
ON Customers.CustomerID = Orders.CustomerID; |
||||
``` |
||||
|
||||
## RIGHT (OUTER) JOIN: |
||||
|
||||
Returns all records from the right table, and the matched records from the left table. Also returns null if there is no match. Example: |
||||
|
||||
```sql |
||||
SELECT Orders.OrderID, Customers.CustomerName |
||||
FROM Orders |
||||
RIGHT JOIN Customers |
||||
ON Orders.CustomerID = Customers.CustomerID; |
||||
``` |
||||
## FULL (OUTER) JOIN: |
||||
|
||||
Returns all records when there is a match in either left (table1) or right (table2) table records. Also returns null if there is no match. Example: |
||||
|
||||
```sql |
||||
SELECT Customers.CustomerName, Orders.OrderID |
||||
FROM Customers |
||||
FULL OUTER JOIN Orders |
||||
ON Customers.CustomerID = Orders.CustomerID; |
||||
``` |
||||
## SELF JOIN: |
||||
|
||||
Self join is a regular join, but the table is joined with itself. Example: |
||||
|
||||
```sql |
||||
SELECT A.CustomerName AS CustomerName1, B.CustomerName AS CustomerName2, A.City |
||||
FROM Customers A, Customers B |
||||
WHERE A.CustomerID <> B.CustomerID |
||||
AND A.City = B.City; |
||||
``` |
||||
|
||||
**Note**: JOINS can be used with SELECT, UPDATE, and DELETE statements. |
||||
@ -0,0 +1,74 @@ |
||||
# Scalar |
||||
|
||||
In SQL, a scalar type is a type that holds a single value as opposed to composite types that hold multiple values. In simpler terms, scalar types represent a single unit of data. |
||||
|
||||
Some common examples of scalar types in SQL include: |
||||
|
||||
- Integers (`INT`) |
||||
- Floating-point numbers (`FLOAT`) |
||||
- Strings (`VARCHAR`, `CHAR`) |
||||
- Date and Time (`DATE`, `TIME`) |
||||
- Boolean (`BOOL`) |
||||
|
||||
## Examples |
||||
|
||||
Here is how you can define different scalar types in SQL: |
||||
|
||||
## Integers |
||||
|
||||
An integer can be defined using the INT type. Here is an example of how to declare an integer: |
||||
|
||||
```sql |
||||
CREATE TABLE Employees ( |
||||
EmployeeID INT, |
||||
FirstName VARCHAR(50), |
||||
LastName VARCHAR(50) |
||||
); |
||||
``` |
||||
|
||||
## Floating-Point Numbers |
||||
|
||||
Floating-point numbers can be defined using the FLOAT or REAL type. Here is an example of how to declare a floating-point number: |
||||
|
||||
```sql |
||||
CREATE TABLE Products ( |
||||
ProductID INT, |
||||
Price FLOAT |
||||
); |
||||
``` |
||||
|
||||
## Strings |
||||
|
||||
Strings can be defined using the CHAR, VARCHAR, or TEXT type. Here is an example of how to declare a string: |
||||
|
||||
```sql |
||||
CREATE TABLE Employees ( |
||||
EmployeeID INT, |
||||
FirstName VARCHAR(50), |
||||
LastName VARCHAR(50) |
||||
); |
||||
``` |
||||
|
||||
## Date and Time |
||||
|
||||
The DATE, TIME or DATETIME type can be used to define dates and times: |
||||
|
||||
```sql |
||||
CREATE TABLE Orders ( |
||||
OrderID INT, |
||||
OrderDate DATE |
||||
); |
||||
``` |
||||
|
||||
## Boolean |
||||
|
||||
Booleans can be declared using the BOOL or BOOLEAN type. They hold either `TRUE` or `FALSE`. |
||||
|
||||
```sql |
||||
CREATE TABLE Employees ( |
||||
EmployeeID INT, |
||||
IsActive BOOL |
||||
); |
||||
``` |
||||
|
||||
Remember, the way these types are declared might slightly differ based on the SQL dialect you are using. It's crucial to refer to the specific documentation of the SQL flavor you're working with for the precise syntax and behavior. |
||||
@ -0,0 +1,39 @@ |
||||
# Column |
||||
|
||||
In SQL, columns are used to categorize the data in a table. A column serves as a structure that stores a specific type of data (ints, str, bool, etc.) in a table. Each column in a table is designed with a type, which configures the data that it can hold. Using the right column types and size can help to maintain data integrity and optimize performance. |
||||
|
||||
## **Common SQL Column Types** |
||||
|
||||
1. **CHAR(n)** - It is a fixed-length character string that holds `n` characters. The size can be 1 to 255. For example, |
||||
```sql |
||||
CREATE TABLE Employee(ID CHAR(25)); |
||||
``` |
||||
|
||||
2. **VARCHAR(n)** - A variable-length character string up to `n` characters where `n` can be from 1 to 255. For example, |
||||
```sql |
||||
CREATE TABLE Employee(ID VARCHAR(100)); |
||||
``` |
||||
|
||||
3. **INT** - This type is used for integers. For example, |
||||
```sql |
||||
CREATE TABLE Customers(Age INT); |
||||
``` |
||||
|
||||
4. **DECIMAL(p,s)** - This is a decimal type used for precision and scale. `p` represents the total number of digits and `s` for numbers after the decimal. For example, |
||||
```sql |
||||
CREATE TABLE Products(Price DECIMAL(5,2)); |
||||
``` |
||||
|
||||
5. **DATE** - This type is used for date format 'YYYY-MM-DD'. For example, |
||||
```sql |
||||
CREATE TABLE Orders(OrderedDate DATE); |
||||
``` |
||||
|
||||
6. **BOOL** - It stores Boolean data types. It can only take `True` or `False` values. For example, |
||||
```sql |
||||
CREATE TABLE Users(IsActive BOOL); |
||||
``` |
||||
|
||||
In SQL, the column type helps in interpreting what kind of data to store in which column, whether it's number, text, date, or logical data. Remember, a table contains multiple columns and each column should have its unique name. |
||||
|
||||
When creating a table, you should specify the column names, types, and maximum length of the type [if required]. |
||||
@ -0,0 +1,43 @@ |
||||
# Row |
||||
|
||||
In SQL, a "row" refers to a record in a table. Each row in a table represents a set of related data, and every row in the table has the same structure. |
||||
|
||||
For instance, in a table named "customers", a row may represent one customer, with columns containing information like ID, name, address, email, etc. |
||||
|
||||
Here is a conceptual SQL table: |
||||
|
||||
| ID | NAME | ADDRESS | EMAIL | |
||||
|----|------|---------|-------| |
||||
| 1 | John | NY | john@example.com | |
||||
| 2 | Jane | LA | jane@example.com | |
||||
| 3 | Jim | Chicago | jim@example.com | |
||||
|
||||
Each of these line of data is referred to as a 'row' in the SQL table. |
||||
|
||||
To select a row, you would use a `SELECT` statement. Here's an example of how you might select a row: |
||||
|
||||
```sql |
||||
SELECT * |
||||
FROM customers |
||||
WHERE ID = 1; |
||||
``` |
||||
|
||||
This would output: |
||||
|
||||
| ID | Name | ADDRESS | Email | |
||||
|---|------|---------|--------| |
||||
| 1 | John | NY | john@example.com | |
||||
|
||||
The `*` in the statement refers to all columns. If you want to only select specific columns, you can replace `*` with the column name(s): |
||||
|
||||
```sql |
||||
SELECT NAME, EMAIL |
||||
FROM customers |
||||
WHERE ID = 1; |
||||
``` |
||||
|
||||
In this case, the output would be: |
||||
|
||||
| Name | Email | |
||||
|-----|--------| |
||||
| John | john@example.com | |
||||
@ -0,0 +1,48 @@ |
||||
# Table |
||||
|
||||
In SQL, a table is a collection of related data held in a structured format within a database. It consists of rows (records) and columns (fields). |
||||
|
||||
A table is defined by its name and the nature of data it will hold, i.e., each field has a name and a specific data type. |
||||
|
||||
## Table Creation |
||||
|
||||
You can create a table using the `CREATE TABLE` SQL statement. The syntax is as follows: |
||||
|
||||
```sql |
||||
CREATE TABLE table_name ( |
||||
column1 datatype, |
||||
column2 datatype, |
||||
column3 datatype, |
||||
.... |
||||
); |
||||
``` |
||||
Here, `table_name` is the name of the table, `column1`, `column2`... are the names of the columns, and `datatype` specifies the type of data the column can hold (e.g., varchar, integer, date, etc.). |
||||
|
||||
## Table Manipulation |
||||
|
||||
Once a table has been created, the `INSERT INTO` statement is used to insert new rows of data into the table. |
||||
|
||||
```sql |
||||
INSERT INTO table_name (column1, column2, column3,...) |
||||
VALUES (value1, value2, value3,...); |
||||
``` |
||||
The `SELECT` statement is used to select data from the table. |
||||
|
||||
```sql |
||||
SELECT column1, column2,... |
||||
FROM table_name; |
||||
``` |
||||
The `UPDATE` statement is used to modify existing records. |
||||
|
||||
```sql |
||||
UPDATE table_name |
||||
SET column1 = value1, column2 = value2,... |
||||
WHERE condition; |
||||
``` |
||||
And, finally, the `DELETE` statement is used to delete existing records. |
||||
|
||||
```sql |
||||
DELETE FROM table_name WHERE condition; |
||||
``` |
||||
|
||||
These basic operations allow for full manipulation of tables in SQL, letting users to manage their data effectively. |
||||
@ -0,0 +1,62 @@ |
||||
# Types of Sub Queries |
||||
|
||||
Subqueries, sometimes referred to as inner queries or nested queries, are queries that are embedded within the clause of another SQL query. There are different types of SQL subqueries that are frequently used including Scalar, Row, Column, and Table subqueries. |
||||
|
||||
## Scalar Subqueries |
||||
|
||||
A scalar subquery is a query that returns exactly one column with a single value. This type of subquery can be used anywhere in your SQL where expressions are allowed. |
||||
|
||||
Example: |
||||
|
||||
```sql |
||||
SELECT column_name [, column_name ] |
||||
FROM table1 [, table2 ] |
||||
WHERE column_name operator |
||||
(SELECT column_name [, column_name ] |
||||
FROM table_name |
||||
WHERE condition); |
||||
``` |
||||
|
||||
## Row Subqueries |
||||
|
||||
Row subqueries are used to return one or more rows to the outer SQL select query. However, the subquery returns multiple columns and rows, so it cannot be directly used where scalar expressions are used. |
||||
|
||||
Example: |
||||
|
||||
```sql |
||||
SELECT column_name [, column_name ] |
||||
FROM table1 [, table2 ] |
||||
WHERE (column_name [, column_name ]) |
||||
IN (SELECT column_name [, column_name ] |
||||
FROM table_name |
||||
WHERE condition); |
||||
``` |
||||
|
||||
## Column Subqueries |
||||
|
||||
Column Subqueries are used to return one or more columns to the outer SQL select query. They are used when the subquery is expected to return more than one column to the main query. |
||||
|
||||
Example: |
||||
|
||||
```sql |
||||
SELECT column_name [, column_name ] |
||||
FROM table1 [, table2 ] |
||||
WHERE (SELECT column_name [, column_name ] |
||||
FROM table_name |
||||
WHERE condition); |
||||
``` |
||||
|
||||
## Table Subqueries |
||||
|
||||
Table subqueries are used in the FROM clause and return a table that can be used as a table-reference in an SQL statement. They come in handy when you want to perform operations such as joining multiple tables, union data from multiple sources, etc. |
||||
|
||||
Example: |
||||
|
||||
```sql |
||||
SELECT column_name [, column_name ] |
||||
FROM |
||||
(SELECT column_name [, column_name ] |
||||
FROM table1 [, table2 ]) |
||||
WHERE condition; |
||||
``` |
||||
Remember that not all SQL databases support all types of subqueries. Learning how and when to utilize each form is an essential aspect of constructing effective SQL queries. |
||||
@ -0,0 +1,42 @@ |
||||
# Nested Subqueries |
||||
|
||||
In SQL, a subquery is a query that is nested inside a main query. If a subquery is nested inside another subquery, it is called a nested subquery. They can be used in SELECT, INSERT, UPDATE, or DELETE statements or inside another subquery. |
||||
|
||||
Nested subqueries can get complicated quickly, but they are essential for performing complex database tasks. |
||||
|
||||
## Basic Syntax: |
||||
|
||||
```sql |
||||
SELECT column_name [, column_name ] |
||||
FROM table1 [, table2 ] |
||||
WHERE column_name OPERATOR |
||||
(SELECT column_name [, column_name ] |
||||
FROM table1 [, table2 ] |
||||
[WHERE]) |
||||
``` |
||||
|
||||
## How They Work: |
||||
|
||||
In a nested subquery, the inner subquery will run first and its result will be used to run the outer query. |
||||
|
||||
## Example: |
||||
|
||||
Here's an example where we want to find the customer names who made orders above the average order amount. |
||||
|
||||
```sql |
||||
SELECT CustomerName,Country |
||||
FROM Customers |
||||
WHERE CustomerID IN |
||||
(SELECT CustomerID |
||||
FROM Orders |
||||
WHERE Amount>(SELECT AVG(Amount) |
||||
FROM Orders)) |
||||
``` |
||||
|
||||
In the above code: |
||||
|
||||
- The innermost query calculates the average order amount. |
||||
- The middle subquery finds the `CustomerID`s from the `Orders` table where the order `Amount` is greater than the average. |
||||
- The outer query then gets the `CustomerName` from the `Customers` table where the `CustomerID` is in the list of `CustomerID`s fetched from the middle subquery. |
||||
|
||||
These are the basic aspects of nested subqueries in SQL. They can go as deep as the task requires, but keep in mind that too many nested subqueries can cause performance issues. |
||||
@ -0,0 +1,33 @@ |
||||
# Correlated Subqueries |
||||
|
||||
In SQL, a correlated subquery is a subquery that uses values from the outer query in its WHERE clause. The correlated subquery is evaluated once for each row processed by the outer query. It exists because it depends on the outer query and it cannot execute independently of the outer query because the subquery is correlated with the outer query as it uses its column in its WHERE clause. |
||||
|
||||
## Syntax: |
||||
|
||||
```sql |
||||
SELECT column_name [, column_name...] |
||||
FROM table1 [, table2...] |
||||
WHERE column_name OPERATOR |
||||
(SELECT column_name [, column_name...] |
||||
FROM table_name |
||||
WHERE condition [table1.column_name = table2.column_name...]); |
||||
``` |
||||
|
||||
## Code Example |
||||
|
||||
For instance, if you want to get the employees whose salaries are above their department's average salaries, it can be queried with a correlated subquery as follows: |
||||
|
||||
```sql |
||||
SELECT e1.employee_name, e1.salary |
||||
FROM employee e1 |
||||
WHERE salary > |
||||
(SELECT AVG(salary) |
||||
FROM employee e2 |
||||
WHERE e1.department = e2.department); |
||||
``` |
||||
|
||||
In the example above, the correlated subquery (the inner query) calculates the average salary for each department. The outer query then compares the salary of each employee to the average salary of their respective department. It returns the employees whose salaries are above their department's average. The correlated subquery is executed once for each row selected by the outer query. |
||||
|
||||
Also note that `e1` and `e2` are the aliases of the `employee` table so that we can use it in both the inner query and outer query. Here, `e2.department` in the inner query comes from the outer query's `e1.department`. |
||||
|
||||
Thus, a correlated subquery is a subquery that depends on the outer SQL query for its values. This means that the subquery is run once for every Row in the outer query, often resulting in quite a bit of processing, and thus slower results. |
||||
@ -0,0 +1,60 @@ |
||||
# Sub Queries |
||||
|
||||
In SQL, a subquery is a query embedded within another SQL query. You can alternately call it a nested or an inner query. The containing query is often referred to as the outer query. Subqueries are utilized to retrieve data that will be used in the main query as a condition to further restrict the data to be retrieved. |
||||
|
||||
Subqueries can be used in various parts of a query, including: |
||||
|
||||
- **SELECT** statement |
||||
- **FROM** clause |
||||
- **WHERE** clause |
||||
- **GROUP BY** clause |
||||
- **HAVING** clause |
||||
|
||||
## Syntax |
||||
|
||||
In general, the syntax can be written as: |
||||
|
||||
```sql |
||||
SELECT column_name [, column_name] |
||||
FROM table1 [, table2 ] |
||||
WHERE column_name OPERATOR |
||||
(SELECT column_name [, column_name] |
||||
FROM table1 [, table2 ] |
||||
[WHERE]) |
||||
``` |
||||
|
||||
## Types of Subqueries |
||||
|
||||
1. **Scalar Subquery**: It returns single value. |
||||
|
||||
```sql |
||||
SELECT name |
||||
FROM student |
||||
WHERE roll_id = (SELECT roll_id FROM student WHERE name='John'); |
||||
``` |
||||
|
||||
2. **Row subquery**: It returns single row of two or more values. |
||||
|
||||
```sql |
||||
SELECT * FROM student |
||||
WHERE (roll_id, age)=(SELECT MIN(roll_id),MIN(age) FROM student); |
||||
``` |
||||
|
||||
3. **Column subquery**: It returns single column value which is more than one row and one column. |
||||
|
||||
```sql |
||||
SELECT name, age FROM student |
||||
WHERE name=(SELECT name FROM student); |
||||
``` |
||||
|
||||
4. **Table subquery**: It returns more than one row and more than one column. |
||||
|
||||
```sql |
||||
SELECT name, age |
||||
FROM student |
||||
WHERE (name, age) IN (SELECT name, age FROM student); |
||||
``` |
||||
|
||||
## General Note |
||||
|
||||
Subqueries can be either correlated or uncorrelated. A correlated subquery is a subquery that uses values from the outer query. Conversely, an uncorrelated subquery is a subquery that can be run independently of the outer query. |
||||
@ -0,0 +1,71 @@ |
||||
# Numeric |
||||
|
||||
SQL numeric functions are used to perform operations on numeric data types such as integer, decimal, and float. They're fundamental in manipulating data in SQL commands and are commonly used in `SELECT`, `UPDATE`, `DELETE` and `INSERT` statements. |
||||
|
||||
## Examples of SQL Numeric Functions: |
||||
|
||||
1. **ABS() Function:** This function returns the absolute (positive) value of a number. |
||||
|
||||
```sql |
||||
SELECT ABS(-243); |
||||
``` |
||||
Output: |
||||
|
||||
243 |
||||
|
||||
2. **Avg() Function:** This function returns the average value of a column. |
||||
|
||||
```sql |
||||
SELECT AVG(price) FROM products; |
||||
``` |
||||
|
||||
3. **COUNT() Function:** This function returns the number of rows that matches a specified criterion. |
||||
|
||||
```sql |
||||
SELECT COUNT(productID) FROM products; |
||||
``` |
||||
|
||||
4. **SUM() Function:** This function returns the total sum of a numeric column. |
||||
|
||||
```sql |
||||
SELECT SUM(price) FROM products; |
||||
``` |
||||
|
||||
5. **MIN() & MAX() Functions:** MIN() function returns the smallest value of the selected column, and MAX() function returns the largest value of the selected column. |
||||
|
||||
```sql |
||||
SELECT MIN(price) FROM products; |
||||
SELECT MAX(price) FROM products; |
||||
``` |
||||
|
||||
6. **ROUND() Function:** This function is used to round a numeric field to the nearest integer, you can, however, specify the number of decimals to be returned. |
||||
|
||||
```sql |
||||
SELECT ROUND(price, 2) FROM products; |
||||
``` |
||||
|
||||
7. **CEILING() Function:** This function returns the smallest integer which is greater than, or equal to, the specified numeric expression. |
||||
|
||||
```sql |
||||
SELECT CEILING(price) FROM products; |
||||
``` |
||||
|
||||
8. **FLOOR() Function:** This function returns the largest integer which is less than, or equal to, the specified numeric expression. |
||||
|
||||
```sql |
||||
SELECT FLOOR(price) FROM products; |
||||
``` |
||||
|
||||
9. **SQRT() Function:** This function returns the square root of a number. |
||||
|
||||
```sql |
||||
SELECT SQRT(price) FROM products; |
||||
``` |
||||
|
||||
10. **PI() Function:** This function returns the constant Pi. |
||||
|
||||
```sql |
||||
SELECT PI(); |
||||
``` |
||||
|
||||
These are just a few examples, SQL supports many more mathematical functions such as SIN, COS, TAN, COT, POWER, etc. Understanding and using these SQL numeric functions allows you to perform complex operations on the numeric data in your SQL tables. |
||||
@ -0,0 +1,45 @@ |
||||
# ROUND |
||||
|
||||
The `ROUND` function in SQL is used to round a numeric field to the nearest specified decimal or integer. |
||||
|
||||
Most usually, `ROUND` accepts two arguments. The first one is the value that needs to be rounded, and the second is the number of decimal places to which the first argument will be rounded off. When dealing with decimals, SQL will round up when the number after the decimal point is 5 or higher, whereas it will round down if it's less than 5. |
||||
|
||||
## Syntax |
||||
|
||||
The basic syntax for `ROUND` can be described as follows: |
||||
|
||||
```sql |
||||
ROUND ( numeric_expression, length [ , function ] ) |
||||
``` |
||||
- `numeric_expression`: A floating point number to round. |
||||
- `length`: The precision to which `numeric_expression` is to be rounded. When `length` is a positive number, rounding affects the right side of the decimal point. If `length` is negative, rounding affects the left side of the decimal point. |
||||
- `function`: Optional parameter to determine the operation to perform. If this is omitted or 0, the `numeric_expression` is rounded. If this is 1, the `numeric_expression` is truncated. |
||||
|
||||
## Example 1: |
||||
|
||||
Round off a decimal to the nearest whole number. |
||||
|
||||
```sql |
||||
SELECT ROUND(125.215); |
||||
``` |
||||
This will result in `125`. |
||||
|
||||
## Example 2: |
||||
|
||||
Round off a number to a specified decimal place. |
||||
|
||||
```sql |
||||
SELECT ROUND(125.215, 1); |
||||
``` |
||||
This will result in `125.2` as the second decimal place (5) is less than 5. |
||||
|
||||
## Example 3: |
||||
|
||||
Round off the left side of the decimal. |
||||
|
||||
```sql |
||||
SELECT ROUND(125.215, -2); |
||||
``` |
||||
This will result in `100` as rounding now affects digits before the decimal point. |
||||
|
||||
Whenever you need to round off numeric data in SQL, the `ROUND` function is a valuable tool to have in your kit. It proficiently handles both positive and negative rounding, and its simple syntax makes it extremely user-friendly. |
||||
@ -0,0 +1,41 @@ |
||||
# CONCAT |
||||
|
||||
`CONCAT` is a SQL function that allows you to concatenate, or join, two or more strings together. This is extremely useful whenever you need to combine text from multiple columns into a single column. |
||||
|
||||
The syntax for the `CONCAT` function is quite simple: |
||||
|
||||
```sql |
||||
CONCAT(string1, string2, ..., string_n) |
||||
``` |
||||
|
||||
This function accepts as input any number of string arguments, from two to as many as needed, and returns a new string which is the result of all the input strings joined together. The strings are concatenated in the order in which they are passed to the function. |
||||
|
||||
Here's a simple example: |
||||
|
||||
```sql |
||||
SELECT CONCAT('Hello', ' ', 'World'); |
||||
``` |
||||
|
||||
This will return the string: |
||||
|
||||
``` |
||||
'Hello World' |
||||
``` |
||||
|
||||
You can also use `CONCAT` with columns from a table: |
||||
|
||||
```sql |
||||
SELECT CONCAT(first_name, ' ', last_name) AS full_name |
||||
FROM employees; |
||||
``` |
||||
|
||||
The above query will return a new column `full_name` which is the result of `first_name` and `last_name` with a space in between. If `first_name` is 'John' and `last_name` is 'Doe', the returned full name would be 'John Doe'. |
||||
|
||||
However, keep in mind that `CONCAT` will return `NULL` if any of the input strings is `NULL`. To avoid this, you can use the `CONCAT_WS` function which accepts a separator as the first argument and then a list of strings to concatenate. |
||||
|
||||
```sql |
||||
SELECT CONCAT_WS(' ', first_name, last_name) AS full_name |
||||
FROM employees; |
||||
``` |
||||
|
||||
The `CONCAT_WS` function will ignore any `NULL` values, only joining the non-NULL values with the provided separator. Hence, 'John NULL' would become just 'John'. |
||||
@ -0,0 +1,53 @@ |
||||
# LENGTH |
||||
|
||||
In SQL, `LENGTH` is a built-in function that allows you to find the number of characters in a string or the length of a string. |
||||
|
||||
Syntax: |
||||
|
||||
```sql |
||||
LENGTH ( string ) |
||||
``` |
||||
Here, `string` can be any string literal, column or expression resulting in a string. |
||||
|
||||
## Examples |
||||
|
||||
Consider an "employees" table: |
||||
|
||||
| id | first_name | last_name | |
||||
|----|------------|-----------| |
||||
| 1 | John | Doe | |
||||
| 2 | Jane | Smith | |
||||
| 3 | Alice | Murphy | |
||||
|
||||
To compute the length of the first_name field for all records, use the following SQL statement: |
||||
```sql |
||||
SELECT first_name, LENGTH(first_name) as length_of_first_name |
||||
FROM employees; |
||||
``` |
||||
Output: |
||||
|
||||
| first_name | length_of_first_name | |
||||
|------------|----------------------| |
||||
| John | 4 | |
||||
| Jane | 4 | |
||||
| Alice | 5 | |
||||
|
||||
## Usage with DISTINCT |
||||
`LENGTH` can also be used in conjunction with `DISTINCT` to find the number of distinct lengths of a specific field. |
||||
```sql |
||||
SELECT DISTINCT LENGTH(first_name) as distinct_length_of_first_name |
||||
FROM employees; |
||||
``` |
||||
|
||||
## Usage with WHERE Clause |
||||
|
||||
It can work in the WHERE clause to return only those records where the length of a specific field meets a certain condition. |
||||
```sql |
||||
SELECT * |
||||
FROM employees |
||||
WHERE LENGTH(first_name) > 4; |
||||
``` |
||||
|
||||
Do note that the `LENGTH` function may return different results in different SQL systems due to character set and collation differences. In some systems, `LENGTH()` returns length in characters while in others it could return length in bytes. |
||||
|
||||
For example, MySQL has separate `CHAR_LENGTH()` and `LENGTH()` functions. `CHAR_LENGTH()` returns the length of the string in characters, while `LENGTH()` in MySQL returns the length of the string in bytes. This can make a difference if your string includes multibyte characters (like UTF-8). In such scenarios, it's always recommended to be sure how your specific SQL system implements `LENGTH` function. |
||||
@ -0,0 +1,61 @@ |
||||
# SUBSTRING |
||||
|
||||
The SQL `SUBSTRING` function is used to extract a part of a string, where you can specify the start position and the length of the text. This function can be very beneficial when you only need a specific part of a string. |
||||
|
||||
## Syntax |
||||
|
||||
The standardized SQL syntax for `SUBSTRING` is as follows: |
||||
|
||||
```sql |
||||
SUBSTRING(string, start, length) |
||||
``` |
||||
|
||||
Where: |
||||
|
||||
- `string` is the source string from which you want to extract. |
||||
- `start` is the position to start extraction from. The first position in the string is always 1. |
||||
- `length` is the number of characters to extract. |
||||
|
||||
## Usage |
||||
|
||||
For instance, if you want to extract the first 5 characters from the string 'Hello World': |
||||
|
||||
```sql |
||||
SELECT SUBSTRING('Hello World', 1, 5) as ExtractedString; |
||||
``` |
||||
|
||||
Result: |
||||
|
||||
```sql |
||||
| ExtractedString | |
||||
| --------------- | |
||||
| Hello | |
||||
``` |
||||
|
||||
You can also use `SUBSTRING` on table columns, like so: |
||||
|
||||
```sql |
||||
SELECT SUBSTRING(column_name, start, length) FROM table_name; |
||||
``` |
||||
|
||||
## SUBSTRING with FROM and FOR |
||||
|
||||
In some database systems (like PostgreSQL and SQL Server), the `SUBSTRING` function uses a different syntax: |
||||
|
||||
```sql |
||||
SUBSTRING(string FROM start FOR length) |
||||
``` |
||||
|
||||
This format functions the same way as the previously mentioned syntax. |
||||
|
||||
For example: |
||||
|
||||
```sql |
||||
SELECT SUBSTRING('Hello World' FROM 1 FOR 5) as ExtractedString; |
||||
``` |
||||
|
||||
This would yield the same result as the previous example - 'Hello'. |
||||
|
||||
## Note |
||||
|
||||
SQL is case-insensitive, meaning `SUBSTRING`, `substring`, and `Substring` will all function the same way. |
||||
@ -0,0 +1,45 @@ |
||||
# REPLACE |
||||
|
||||
You can use the `REPLACE()` function in SQL to substitute all occurrences of a specified string. |
||||
|
||||
**Synopsis** |
||||
|
||||
`REPLACE(input_string, string_to_replace, replacement_string)` |
||||
|
||||
**Parameters** |
||||
|
||||
- `input_string`: This is the original string where you want to replace some characters. |
||||
- `string_to_replace`: This is the string that will be searched for in the original string. |
||||
- `replacement_string`: This is the string that will replace the `string_to_replace` in the original string. |
||||
|
||||
The `REPLACE()` function is handy when it comes to manipulating and modifying data in various ways, particularly when used in combination with other SQL data-manipulation functions. |
||||
|
||||
**Examples** |
||||
|
||||
Suppose we have the following table, `Employees`: |
||||
|
||||
| EmpId | EmpName | |
||||
|-------|---------------------| |
||||
| 1 | John Doe | |
||||
| 2 | Jane Doe | |
||||
| 3 | Jim Smith Doe | |
||||
| 4 | Jennifer Doe Smith | |
||||
|
||||
Here's how you can use the `REPLACE()` function: |
||||
|
||||
```sql |
||||
SELECT EmpId, EmpName, |
||||
REPLACE(EmpName, 'Doe', 'Roe') as ModifiedName |
||||
FROM Employees; |
||||
``` |
||||
|
||||
After the execution of the above SQL, we will receive: |
||||
|
||||
| EmpId | EmpName | ModifiedName | |
||||
|-------|--------------------|---------------------| |
||||
| 1 | John Doe | John Roe | |
||||
| 2 | Jane Doe | Jane Roe | |
||||
| 3 | Jim Smith Doe | Jim Smith Roe | |
||||
| 4 | Jennifer Doe Smith | Jennifer Roe Smith | |
||||
|
||||
You can see that all occurrences of 'Doe' are replaced with 'Roe'. |
||||
@ -0,0 +1,35 @@ |
||||
# UPPER |
||||
|
||||
`UPPER()` is a built-in string function in SQL. As the name suggests, it is used to convert all letters in a specified string to uppercase. If the string already consists of all uppercase characters, the function will return the original string. |
||||
|
||||
Syntax for this function is: |
||||
|
||||
```sql |
||||
UPPER(string) |
||||
``` |
||||
|
||||
Here 'string' can be a string value or a column of a table of string(s) type. |
||||
|
||||
Let's assume a table 'students' with column 'name' as below: |
||||
|
||||
| name | |
||||
|------------| |
||||
| John Doe | |
||||
| Jane Smith | |
||||
| Kelly Will | |
||||
|
||||
If we want all the names in uppercase, we'll use `UPPER()` function as: |
||||
|
||||
```sql |
||||
SELECT UPPER(name) as 'Upper Case Name' FROM students; |
||||
``` |
||||
|
||||
And we will get: |
||||
|
||||
| Upper Case Name | |
||||
|----------------| |
||||
| JOHN DOE | |
||||
| JANE SMITH | |
||||
| KELLY WILL | |
||||
|
||||
So, `UPPER()` function helps us to bring an entire string to uppercase for easier comparison and sorting. |
||||
@ -0,0 +1,38 @@ |
||||
# LOWER |
||||
|
||||
`LOWER` is a built-in function in SQL used to return all uppercase character(s) in a string to lowercase. It can be quite useful when performing case-insensitive comparisons or searches in your queries. |
||||
|
||||
## Syntax: |
||||
|
||||
The basic syntax for `LOWER` in SQL is: |
||||
|
||||
``` |
||||
LOWER(string) |
||||
``` |
||||
|
||||
Here, 'string' can be a literal string or a column of a table, and the function will return the string with all alphabetic characters converted to lowercase. |
||||
|
||||
## Example: |
||||
|
||||
Let's take a look at a very basic example. Assuming we have the following string "SQL is BAE!" and we want to convert it to lower case. |
||||
|
||||
```sql |
||||
SELECT LOWER('SQL is BAE!') AS LowerCaseString; |
||||
``` |
||||
|
||||
Output: |
||||
```sql |
||||
lowercasestring |
||||
---------------- |
||||
sql is bae! |
||||
``` |
||||
|
||||
If you are using a column from a table, let's say we have a table 'students' with a column 'Name' and we want to convert all the entries in that column to lowercase: |
||||
|
||||
```sql |
||||
SELECT LOWER(Name) AS LowerCaseName FROM students; |
||||
``` |
||||
|
||||
Here, the LOWER function will return all the names from the 'Name' column in the 'students' table in their lowercase forms. |
||||
|
||||
Remember, the `LOWER` function doesn't affect the numbers and special characters in the input string, it only converts uppercase alphabetical characters to lowercase. |
||||
@ -0,0 +1,91 @@ |
||||
# String Functions |
||||
|
||||
In SQL, you can perform various operations on strings, including extracting a string, combining two or more strings, and converting a case of a string. |
||||
|
||||
## CONCAT Function |
||||
|
||||
The CONCAT function combines two or more strings into one string. The following is the syntax: |
||||
|
||||
```sql |
||||
CONCAT(string1, string2, ...., string_n) |
||||
``` |
||||
|
||||
Example: |
||||
|
||||
```sql |
||||
SELECT CONCAT('Hello ', 'World'); |
||||
``` |
||||
|
||||
The output of the above SQL statement will be 'Hello World'. |
||||
|
||||
## SUBSTRING Function |
||||
|
||||
The SUBSTRING function extracts a string from a given string. The syntax looks as follows: |
||||
|
||||
```sql |
||||
SUBSTRING(string, start, length) |
||||
``` |
||||
|
||||
Example: |
||||
|
||||
```sql |
||||
SELECT SUBSTRING('SQL Tutorial', 1, 3); |
||||
``` |
||||
|
||||
The output of the above query will be 'SQL'. |
||||
|
||||
## LENGTH Function |
||||
|
||||
The LENGTH function returns the length of a string. The syntax is: |
||||
|
||||
```sql |
||||
LENGTH(string) |
||||
``` |
||||
|
||||
Example: |
||||
|
||||
```sql |
||||
SELECT LENGTH('Hello World'); |
||||
``` |
||||
|
||||
The output of the above SQL statement will be 11. |
||||
|
||||
## UPPER and LOWER Function |
||||
|
||||
The UPPER function converts all the letters in a string to uppercase, whereas the LOWER function to lowercase. |
||||
|
||||
Syntax: |
||||
|
||||
```sql |
||||
UPPER(string) |
||||
|
||||
LOWER(string) |
||||
``` |
||||
|
||||
Examples: |
||||
|
||||
```sql |
||||
SELECT UPPER('Hello World'); |
||||
|
||||
SELECT LOWER('Hello World'); |
||||
``` |
||||
The output of the above SQL statements will be 'HELLO WORLD' and 'hello world' respectively. |
||||
|
||||
## TRIM Function |
||||
|
||||
The TRIM function removes leading and trailing spaces of a string. You can also remove other specified characters. |
||||
|
||||
Syntax: |
||||
|
||||
```sql |
||||
TRIM([LEADING|TRAILING|BOTH] [removal_string] FROM original_string) |
||||
``` |
||||
|
||||
Example: |
||||
|
||||
```sql |
||||
SELECT TRIM(' Hello World '); |
||||
SELECT TRIM('h' FROM 'hello'); |
||||
``` |
||||
|
||||
The output of the first query will be 'Hello World' and that of the second query will be 'ello'. |
||||
@ -0,0 +1,24 @@ |
||||
# CEILING |
||||
|
||||
`CEILING` is an advanced SQL function that is used to round up values. The function takes a single argument, which is a numeric or decimal number, and returns the smallest integer that is greater than or equal to the supplied number. |
||||
|
||||
The syntax for using the `CEILING` function is: |
||||
|
||||
```sql |
||||
CEILING (numeric_expression) |
||||
``` |
||||
|
||||
The `numeric_expression` is an expression of the exact numeric or approximate numeric data type categories, or types that can be implicitly converted to one of these categories. |
||||
|
||||
For example, you have a table called 'Products' with a 'Price' column. Here's how you can use the `CEILING` function to round up all the prices to the nearest whole number: |
||||
|
||||
```sql |
||||
SELECT ProductName, Price, CEILING (Price) AS RoundedUpPrice |
||||
FROM Products; |
||||
``` |
||||
|
||||
In this example, if the original price was $10.25, the `RoundedUpPrice` will be $11. This is because the `CEILING` function rounds up the 'Price' value to the nearest whole number. |
||||
|
||||
It's essential to remember that `CEILING` always rounds up. So even if the Price is $10.01, the RoundedUpPrice according to `CEILING` would still be $11. If you want to round to the nearest whole number, you might want to use the `ROUND` function instead. |
||||
|
||||
Another important note is that the return type of `CEILING` will be of the same type as the provided numeric expression. For instance, if you supply a numeric expression of type decimal, the return type will also be of type decimal. |
||||
@ -0,0 +1,47 @@ |
||||
# CASE |
||||
|
||||
`CASE` is a conditional statement in SQL that performs different actions based on different conditions. It allows you to perform IF-THEN-ELSE logic within SQL queries. It can be used in any statement or clause that allows a valid expression. |
||||
|
||||
There are two forms of the `CASE` statement: |
||||
|
||||
1. **Simple CASE expression** - It compares an expression to a set of simple expressions to return a result. |
||||
|
||||
```sql |
||||
SELECT column1, column2, |
||||
(CASE |
||||
WHEN condition1 THEN result1 |
||||
WHEN condition2 THEN result2 |
||||
... |
||||
ELSE result |
||||
END) |
||||
FROM table_name; |
||||
``` |
||||
|
||||
2. **Searched CASE expression** - It evaluates a set of Boolean expressions to return a result. |
||||
|
||||
```sql |
||||
SELECT column1, column2, |
||||
(CASE |
||||
WHEN condition1 THEN result1 |
||||
WHEN condition2 THEN result2 |
||||
... |
||||
ELSE result |
||||
END) |
||||
FROM table_name; |
||||
``` |
||||
|
||||
In both forms, `CASE` returns a result_1, result_2, ..., if condition_1, condition_2, ... is true. If no conditions are true, it returns the value in the `ELSE` clause. If the `ELSE` clause is omitted and no conditions are true, it returns NULL. |
||||
|
||||
Here's a concrete example: |
||||
|
||||
```sql |
||||
SELECT OrderID, Quantity, |
||||
(CASE |
||||
WHEN Quantity > 30 THEN 'Over 30' |
||||
WHEN Quantity = 30 THEN 'Equals 30' |
||||
ELSE 'Under 30' |
||||
END) AS QuantityText |
||||
FROM OrderDetails; |
||||
``` |
||||
|
||||
From the "OrderDetails" table, the statement lists 'OrderID', 'Quantity', and a column named 'QuantityText' that displays 'Over 30' if 'Quantity > 30' or 'Equals 30' if 'Quantity = 30' or 'Under 30' if both conditions are false. |
||||
@ -0,0 +1,40 @@ |
||||
# NULLIF |
||||
|
||||
`NULLIF` is a built-in conditional function in SQL Server. The `NULLIF` function compares two expressions and returns NULL if they are equal or the first expression if they are not. |
||||
|
||||
## Syntax |
||||
|
||||
Here's the syntax of the `NULLIF` function: |
||||
|
||||
```sql |
||||
NULLIF(expression1, expression2); |
||||
``` |
||||
`NULLIF` compares `expression1` to `expression2`. If `expression1` and `expression2` are equal, the function returns NULL. Otherwise, it returns `expression1`. Both expressions must have the same data type. |
||||
|
||||
## Example |
||||
|
||||
Consider the following example: |
||||
|
||||
```sql |
||||
SELECT |
||||
first_name, |
||||
last_name, |
||||
NULLIF(email, 'NA') AS email |
||||
FROM |
||||
users; |
||||
``` |
||||
In this SQL Server `NULLIF` function example, if the field email is 'NA', then NULL would be returned. Otherwise the actual `email` field value is returned. |
||||
|
||||
In another example, consider a division operation: |
||||
|
||||
```sql |
||||
SELECT |
||||
avg_salary, |
||||
NULLIF(avg_salary, 0) AS avg_salary_no_zero |
||||
FROM |
||||
positions; |
||||
``` |
||||
|
||||
In this SQL Server `NULLIF` function example, if `avg_salary` field is 0, then NULL would be returned. This is useful to avoid division by zero errors. |
||||
|
||||
In nutshell, the SQL `NULLIF` function can be handy in many scenarios such as to circumvent division by zero errors or to translate known sentinel values into NULL values that can be handled by SQL's NULL handling functions. |
||||
@ -0,0 +1,28 @@ |
||||
# COALESCE |
||||
|
||||
The `COALESCE` function in SQL is used to manage NULL values in data. It scans from left to right through the arguments and returns the first argument that is not `NULL`. |
||||
|
||||
Syntax: |
||||
```sql |
||||
COALESCE(value1,value2,..., valueN) |
||||
``` |
||||
The `COALESCE` function allows handling the case where you have possible `NULL` values in your data and you want to replace it with some other value. |
||||
|
||||
For instance, here is an example of how you might use `COALESCE`: |
||||
|
||||
```sql |
||||
SELECT product_name, COALESCE(price, 0) AS Price |
||||
FROM products; |
||||
``` |
||||
In this example, if the "price" column for a product entry is `NULL`, it will instead return "0". |
||||
|
||||
Another common use case is using `COALESCE` to find the first non-NULL value in a list: |
||||
|
||||
```sql |
||||
SELECT COALESCE(NULL, NULL, 'third value', 'fourth value'); |
||||
``` |
||||
In this case, it would return "third value", as that's the first non-NULL value in the list. |
||||
|
||||
Remember, `COALESCE` does not update the original data. It only returns the first non-NULL value in the runtime. To update any NULL values permanently, you would need to use an `UPDATE` statement. |
||||
|
||||
The `COALESCE` function in SQL improves the reliability of your queries when null values are involved. Whether it's replacing nulls with default values or finding the earliest valid date, it's a very useful function to grasp. |
||||
@ -0,0 +1,67 @@ |
||||
# Conditional |
||||
|
||||
In SQL, Conditional expressions can be used in the SELECT statement, WHERE clause, and ORDER BY clause to evaluate multiple conditions. These are SQL's version of the common if…then…else statement in other programming languages. |
||||
|
||||
There are two kinds of conditional expressions in SQL: |
||||
|
||||
1. **CASE** expression |
||||
|
||||
The `CASE` expression is a flow-control statement that allows you to add if-else logic to a query. It comes in two forms: simple and searched. |
||||
|
||||
Here is an example of a simple `CASE` expression: |
||||
|
||||
```sql |
||||
SELECT OrderID, Quantity, |
||||
CASE |
||||
WHEN Quantity > 30 THEN 'Over 30' |
||||
ELSE 'Under 30' |
||||
END AS QuantityText |
||||
FROM OrderDetails; |
||||
``` |
||||
A searched `CASE` statement: |
||||
|
||||
```sql |
||||
SELECT FirstName, City, |
||||
CASE |
||||
WHEN City = 'Berlin' THEN 'Germany' |
||||
WHEN City = 'Madrid' THEN 'Spain' |
||||
ELSE 'Unknown' |
||||
END AS Country |
||||
FROM Customers; |
||||
``` |
||||
|
||||
2. **COALESCE** expression |
||||
|
||||
The `COALESCE` function returns the first non-null value in a list. It takes a comma-separated list of values and returns the first value that is not null. |
||||
|
||||
An example of a `COALESCE` statement: |
||||
|
||||
```sql |
||||
SELECT ProductName, |
||||
COALESCE(UnitsOnOrder, 0) As UnitsOnOrder, |
||||
COALESCE(UnitsInStock, 0) As UnitsInStock, |
||||
FROM Products; |
||||
``` |
||||
|
||||
3. **NULLIF** expression |
||||
|
||||
`NULLIF` returns null if the two given expressions are equal. |
||||
|
||||
Example of using `NULLIF`: |
||||
|
||||
```sql |
||||
SELECT NULLIF(5,5) AS Same, |
||||
NULLIF(5,7) AS Different; |
||||
``` |
||||
|
||||
4. **IIF** expression |
||||
|
||||
`IIF` function returns value_true if the condition is TRUE, or value_false if the condition is FALSE. |
||||
|
||||
Example of using `IIF`: |
||||
|
||||
```sql |
||||
SELECT IIF (1>0, 'One is greater than zero', 'One is not greater than zero'); |
||||
``` |
||||
|
||||
These are essential constructs that can greatly increase the flexibility and functionality of your SQL code, particularly when dealing with elaborate conditions and specific data selections. |
||||
@ -0,0 +1,76 @@ |
||||
# DATE |
||||
|
||||
In SQL, DATE is a data type that stores the date. It does not store time information. The format of the date is, 'YYYY-MM-DD'. For instance, '2022-01-01'. SQL provides several functions to handle and manipulate dates. |
||||
|
||||
Below are some common examples of how to use the DATE data type in SQL: |
||||
|
||||
## Create a table with DATE data type |
||||
|
||||
```sql |
||||
CREATE TABLE Orders ( |
||||
OrderId int, |
||||
ProductName varchar(255), |
||||
OrderDate date |
||||
); |
||||
``` |
||||
|
||||
In this example, the OrderDate column uses the DATE data type to store the date of the order. |
||||
|
||||
## Insert a date value into a table |
||||
|
||||
```sql |
||||
INSERT INTO Orders (OrderId, ProductName, OrderDate) |
||||
VALUES (1, 'Product 1', '2022-01-01'); |
||||
``` |
||||
|
||||
This command inserts a new row into the Orders table with a date. |
||||
|
||||
## Retrieve data with a specific date |
||||
|
||||
```sql |
||||
SELECT * FROM Orders |
||||
WHERE OrderDate = '2022-01-01'; |
||||
``` |
||||
|
||||
This command retrieves all orders made on January 1, 2022. |
||||
|
||||
## Update a date value in a table |
||||
|
||||
```sql |
||||
UPDATE Orders |
||||
SET OrderDate = '2022-01-02' |
||||
WHERE OrderId = 1; |
||||
``` |
||||
|
||||
This command updates the date from January 1, 2022 to January 2, 2022, for the order with the order ID 1. |
||||
|
||||
## SQL Date Functions |
||||
|
||||
SQL also provides several built-in functions to work with the DATE data type: |
||||
|
||||
## CURRENT_DATE |
||||
|
||||
Returns the current date. |
||||
|
||||
```sql |
||||
SELECT CURRENT_DATE; |
||||
``` |
||||
|
||||
## DATEADD |
||||
|
||||
Add or subtract a specified time interval from a date. |
||||
|
||||
```sql |
||||
SELECT DATEADD(day, 5, OrderDate) AS "Due Date" |
||||
FROM Orders; |
||||
``` |
||||
In this example, we are adding 5 days to each OrderDate in the table Orders. |
||||
|
||||
## DATEDIFF |
||||
|
||||
Get the difference between two dates. |
||||
|
||||
```sql |
||||
SELECT DATEDIFF(day, '2022-01-01', '2022-01-06') AS "Difference"; |
||||
``` |
||||
It will return 5, that is the difference in days between the two dates. |
||||
@ -0,0 +1,65 @@ |
||||
# TIME |
||||
|
||||
In SQL, TIME data type is used to store time values in the database. It allows you to store hours, minutes, and seconds. The format of a TIME is 'HH:MI:SS'. |
||||
|
||||
## Syntax |
||||
|
||||
Here is the basic syntax to create a field with TIME data type in SQL: |
||||
```sql |
||||
CREATE TABLE table_name ( |
||||
column_name TIME |
||||
); |
||||
``` |
||||
|
||||
You can store data using the following syntax: |
||||
```sql |
||||
INSERT INTO table_name (column_name) values ('17:34:20'); |
||||
``` |
||||
|
||||
## Range |
||||
|
||||
The time range in SQL is '00:00:00' to '23:59:59'. |
||||
|
||||
## Fetching Data |
||||
|
||||
To fetch the data you can use the SELECT statement. For example: |
||||
|
||||
```sql |
||||
SELECT column_name FROM table_name; |
||||
``` |
||||
It will return the time values from the table. |
||||
|
||||
## Functions |
||||
|
||||
SQL provides several functions to work with the TIME data type. Some of them include: |
||||
|
||||
## CURTIME() |
||||
|
||||
Return the current time. |
||||
```sql |
||||
SELECT CURTIME(); |
||||
``` |
||||
|
||||
## ADDTIME() |
||||
|
||||
Add time values. |
||||
```sql |
||||
SELECT ADDTIME('2007-12-31 23:59:59','1 1:1:1'); |
||||
``` |
||||
|
||||
## TIMEDIFF() |
||||
|
||||
Subtract time values. |
||||
```sql |
||||
SELECT TIMEDIFF('2000:01:01 00:00:00', '2000:01:01 00:01:01'); |
||||
``` |
||||
|
||||
## Conversion |
||||
|
||||
Conversion of TIME data type is also possible in SQL. It can be converted into other data types, like INT, and vice versa. Here is a conversion example of TIME to INT: |
||||
|
||||
```sql |
||||
SELECT TIME_TO_SEC('22:23:00'); |
||||
``` |
||||
|
||||
This was a brief summary about "TIME" in SQL. |
||||
@ -0,0 +1,49 @@ |
||||
# DATEPART |
||||
|
||||
`DATEPART` is a useful function in SQL that allows you to extract a specific part of a date or time field. You can use it to get the year, quarter, month, day of the year, day, week, weekday, hour, minute, second, or millisecond from any date or time expression. |
||||
|
||||
Here's the basic syntax of `DATEPART`: |
||||
|
||||
```sql |
||||
DATEPART(datepart, date) |
||||
``` |
||||
|
||||
Here `datepart` is the part of the date that you want to extract, and `date` is the date value from which the part should be extracted. |
||||
|
||||
Here are some examples: |
||||
|
||||
1. Extracting the year from a date: |
||||
|
||||
```sql |
||||
SELECT DATEPART(year, '2021-07-14') AS 'Year'; |
||||
``` |
||||
|
||||
In this example, it would return `2021`. |
||||
|
||||
2. Extracting the month: |
||||
|
||||
```sql |
||||
SELECT DATEPART(month, '2021-07-14') AS 'Month'; |
||||
``` |
||||
|
||||
The result of this command would be `7`. |
||||
|
||||
3. Extracting the day: |
||||
|
||||
```sql |
||||
SELECT DATEPART(day, '2021-07-14') AS 'Day'; |
||||
``` |
||||
|
||||
This would return `14`. |
||||
|
||||
4. Extracting the hour, minute, or second from a datetime: |
||||
|
||||
```sql |
||||
SELECT DATEPART(hour, '2021-07-14T13:30:15') AS 'Hour', |
||||
DATEPART(minute, '2021-07-14T13:30:15') AS 'Minute', |
||||
DATEPART(second, '2021-07-14T13:30:15') AS 'Second'; |
||||
``` |
||||
|
||||
This would return `13`, `30`, and `15` respectively. |
||||
|
||||
Remember, the `DATEPART` function returns an integer value. It is essential when you want to compare or group by a specific part of a date or time field in SQL. |
||||
@ -0,0 +1,45 @@ |
||||
# DATEADD |
||||
|
||||
`DATEADD` is a built-in function in SQL that allows you to add or subtract units of time from a specified date. The function takes three parameters: |
||||
|
||||
- An interval type (such as day, month, year, hour, minute, second) |
||||
- A number (which can be either positive, for future dates, or negative, for past dates) |
||||
- A date from which calculation will be based. |
||||
|
||||
The usage of this function can be especially useful when you need to perform operations on dates, such as finding a date "n" days before or after a specified date, or getting the first or last day of a month. |
||||
|
||||
## Syntax |
||||
|
||||
The generic syntax for `DATEADD` is: |
||||
|
||||
```sql |
||||
DATEADD(interval, number, date) |
||||
``` |
||||
Here's what each param means: |
||||
|
||||
- `interval`: The part of date to which an integer value will be added. This could be a year, quarter, month, day, hour, minute, second, millisecond, microsecond, or nanosecond. |
||||
|
||||
- `number`: The value to add. The value can either be negative to get dates in the past or positive to get dates in the future. |
||||
|
||||
- `date`: The date or datetime expression to which the interval and number are added. |
||||
|
||||
For example, if we want to add three days to the date '2022-01-01', we would write: |
||||
|
||||
```sql |
||||
SELECT DATEADD(day, 3, '2022-01-01') as NewDate |
||||
``` |
||||
|
||||
The result would be: `2022-01-04`. |
||||
|
||||
You can substitute 'day' with any of the accepted interval types to add different units of time. |
||||
|
||||
## Sample Query |
||||
|
||||
If you have a table called `Orders` with a `DateTime` field `OrderDate` and you want to find all orders placed in the next seven days, you can use the `DATEADD` function as follows: |
||||
|
||||
```sql |
||||
SELECT * FROM Orders |
||||
WHERE OrderDate <= DATEADD(day, 7, GETDATE()) |
||||
``` |
||||
|
||||
This will return all orders from now until a week from now. |
||||
@ -0,0 +1,45 @@ |
||||
# TIMESTAMP |
||||
|
||||
SQL `TIMESTAMP` is a data type that allows you to store both date and time. It is typically used to track updates and changes made to a record, providing a chronological time of happenings. |
||||
|
||||
Depending on the SQL platform, the format and storage size can slightly vary. For instance, MySQL uses the 'YYYY-MM-DD HH:MI:SS' format and in PostgreSQL, it's stored as a 'YYYY-MM-DD HH:MI:SS' format but it additionally can store microseconds. |
||||
|
||||
Here is how you can define a column with a `TIMESTAMP` type in an SQL table: |
||||
|
||||
```sql |
||||
CREATE TABLE table_name ( |
||||
column1 TIMESTAMP, |
||||
column2 VARCHAR(100), |
||||
... |
||||
); |
||||
``` |
||||
|
||||
A common use-case of `TIMESTAMP` is to have an automatically updated timestamp each time the row is updated. This can be achieved by setting the `DEFAULT` constraint to `CURRENT_TIMESTAMP`: |
||||
|
||||
```sql |
||||
CREATE TABLE table_name ( |
||||
column1 TIMESTAMP DEFAULT CURRENT_TIMESTAMP, |
||||
column2 VARCHAR(100), |
||||
... |
||||
); |
||||
``` |
||||
|
||||
In MySQL, `ON UPDATE CURRENT_TIMESTAMP` can be used to automatically update the `TIMESTAMP` field to the current date and time whenever there is any change in other fields of the row. |
||||
|
||||
```sql |
||||
CREATE TABLE table_name ( |
||||
column1 TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, |
||||
column2 VARCHAR(100), |
||||
... |
||||
); |
||||
``` |
||||
|
||||
You can also insert or update records with a specific timestamp: |
||||
|
||||
```sql |
||||
INSERT INTO table_name (column1, column2) VALUES ('2019-06-10 10:20:30', 'example data'); |
||||
|
||||
UPDATE table_name SET column1 = '2020-07-20 15:30:45' WHERE column2 = 'example data'; |
||||
``` |
||||
|
||||
Remember that the format of the date and time you enter must correspond to the format used by the SQL platform you are using. |
||||
@ -0,0 +1,47 @@ |
||||
# Date and Time |
||||
|
||||
In SQL, the `DateTime` data type is used to work with dates and times. SQL Server comes with numerous functions for processing dates and times. Some of these include `GETDATE()`, `DATEDIFF()`, `DATEADD()`, `CONVERT()`, and so forth. |
||||
|
||||
## GETDATE() |
||||
|
||||
`GETDATE()` returns the current date and time as a DateTime datatype. It does not require any arguments. |
||||
|
||||
```sql |
||||
SELECT GETDATE() AS CurrentDateTime; |
||||
``` |
||||
|
||||
## DATEDIFF() |
||||
|
||||
`DATEDIFF()` returns the difference between two date values based on the unit of time you want to use. The syntax is `DATEDIFF(datepart, startdate, enddate)`. |
||||
|
||||
```sql |
||||
SELECT DATEDIFF(day, '2022-01-01', '2022-01-15') AS DiffInDays; |
||||
``` |
||||
|
||||
## DATEADD() |
||||
|
||||
`DATEADD()` adds or subtracts a specified time interval from a date. Its syntax is `DATEADD(datepart, number, date)`. |
||||
|
||||
```sql |
||||
SELECT DATEADD(year, 1, '2022-01-01') AS NewDate; |
||||
``` |
||||
|
||||
## CONVERT() |
||||
|
||||
`CONVERT()` is used to convert from one data type to another, and it is commonly used to format DateTime values. Its syntax is `CONVERT(data_type(length), expression, style)`. |
||||
|
||||
```sql |
||||
SELECT CONVERT(VARCHAR(19), GETDATE()) AS FormattedDateTime; |
||||
``` |
||||
Remember to replace `date` with your date in above queries. |
||||
|
||||
## DateTime Format |
||||
|
||||
By using appropriate format codes, SQL allows us to present dates and times in various formats. |
||||
|
||||
```sql |
||||
SELECT FORMAT(GETDATE(), 'MM/dd/yyyy') AS DateFormatted; |
||||
``` |
||||
Also, by using specific column names instead of `GETDATE()`, the same patterns can be applied to DateTime values in your data. |
||||
|
||||
Note: All dates are stored as numeric values under the hood, with the integer portion representing the date and the decimal portion representing the time. Also, different database systems may use slightly different functions for handling dates and times, so be sure to check the documentation for your specific DBMS. |
||||
@ -0,0 +1,30 @@ |
||||
# FLOOR |
||||
|
||||
The SQL `FLOOR` function is used to round down any specific decimal or numeric value to its nearest whole integer. The returned number will be less than or equal to the number given as an argument. |
||||
|
||||
One important aspect to note is that the `FLOOR` function's argument must be a number and it always returns an integer. |
||||
|
||||
## Syntax |
||||
|
||||
The syntax of using the `FLOOR` function in SQL is as follows: |
||||
```sql |
||||
FLOOR (number); |
||||
``` |
||||
|
||||
## Example Usage |
||||
|
||||
Here's a simple example of its usage: |
||||
|
||||
```sql |
||||
SELECT FLOOR(25.75); |
||||
``` |
||||
The above query will return `25` as the result, as that's the nearest integer less than `25.75`. |
||||
|
||||
Suppose we have a table called `Orders` with a column `SalePrice` that includes decimal values. If we wanted to round down the `SalePrice` values to the nearest whole numbers, we could use a query like this: |
||||
|
||||
```sql |
||||
SELECT FLOOR(SalePrice) AS RoundedSalePrice |
||||
FROM Orders; |
||||
``` |
||||
|
||||
This would output a new column `RoundedSalePrice` where all the sale prices have been rounded down to the nearest integers. |
||||
@ -0,0 +1,38 @@ |
||||
# ABS |
||||
|
||||
The `ABS` function in SQL is used to return the absolute value of a number, i.e., the numeric value without its sign. The function takes a single argument which must be a number (integer, float, etc.) and returns the absolute, non-negative equivalent. |
||||
|
||||
The general syntax for the ABS function is as follows: |
||||
|
||||
```sql |
||||
ABS(expression) |
||||
``` |
||||
|
||||
In the syntax above, the `expression` is required and can either be a literal number, a column name, the result of another function, or any valid SQL expression that resolves to a numeric value. |
||||
|
||||
## Examples |
||||
|
||||
Consider a database table `Orders`: |
||||
|
||||
| OrderID | Product | Quantity | |
||||
|---------|---------|----------| |
||||
| 1 | Apple | -5 | |
||||
| 2 | Banana | 10 | |
||||
| 3 | Cherry | -15 | |
||||
|
||||
If you want to get the absolute value of the 'Quantity' column, you could use the `ABS`function like this: |
||||
|
||||
```sql |
||||
SELECT OrderID, Product, ABS(Quantity) as 'Absolute Quantity' |
||||
FROM Orders; |
||||
``` |
||||
|
||||
The output will be: |
||||
|
||||
| OrderID | Product | Absolute Quantity | |
||||
|---------|---------|-------------------| |
||||
| 1 | Apple | 5 | |
||||
| 2 | Banana | 10 | |
||||
| 3 | Cherry | 15 | |
||||
|
||||
As you can see, the negative values in the 'Quantity' column have been converted to positive values by the `ABS` function. |
||||
@ -0,0 +1,33 @@ |
||||
# MOD |
||||
|
||||
The SQL `MOD()` function is a mathematical function that returns the remainder of the values from the division of two numbers. It calculates the modulo operation. This function is very useful when you want to find the remainder value after one number is divided by another. |
||||
|
||||
## Syntax |
||||
|
||||
The syntax of the MOD function in SQL is: |
||||
```sql |
||||
MOD(expression1, expression2) |
||||
``` |
||||
|
||||
- `Expression1` and `Expression2` are the values that you want to apply the function to. |
||||
|
||||
## Basic Usage |
||||
|
||||
For instance, if you want to find the remainder of the division of 15 by 4 you would write: |
||||
```sql |
||||
SELECT MOD(15, 4) as result; |
||||
``` |
||||
The result would be `3` because 3 is the remainder after dividing 15 by 4. |
||||
|
||||
## Usage with Table Columns |
||||
|
||||
The `MOD()` function can also be applied to table columns. Let's imagine that you have a table named "Orders" with an "OrderNumber" column and you want to find the remainder of every order number when divided by 7, you would do: |
||||
|
||||
```sql |
||||
SELECT OrderNumber, MOD(OrderNumber, 7) as result |
||||
FROM Orders; |
||||
``` |
||||
|
||||
This will return a list of all order numbers, along with the remainder when each order number is divided by 7. |
||||
|
||||
Keep in mind that the SQL `MOD()` function may not work in the same way, or might not support all features, in every SQL database. Always refer to the documentation specific to the SQL database you are using. |
||||
@ -0,0 +1,69 @@ |
||||
# Advanced SQL Functions |
||||
|
||||
Advanced SQL functions provide complex data manipulation and query capabilities enabling the user to perform tasks that go beyond the capabilities of basic SQL commands. |
||||
|
||||
## Window Function |
||||
|
||||
Windowing Functions provide the ability to perform calculations across sets of rows related to the current query row. |
||||
|
||||
```sql |
||||
SELECT productName, productLine, buyPrice, |
||||
AVG(buyPrice) OVER(PARTITION BY productLine) as avg_price |
||||
FROM products |
||||
ORDER BY productLine, buyPrice; |
||||
``` |
||||
|
||||
## Aggregate Function |
||||
|
||||
Aggregate functions return a single result row based on groups of rows, rather than on single rows. |
||||
|
||||
```sql |
||||
SELECT COUNT(*) FROM products; |
||||
``` |
||||
|
||||
## Analytic Functions |
||||
|
||||
Analytic functions compute an aggregate value based on a group of rows. They differ from aggregate functions in that they return multiple rows for each group. |
||||
|
||||
```sql |
||||
SELECT department_id, last_name, hire_date, |
||||
COUNT(*) OVER (PARTITION BY department_id) as dept_count, |
||||
RANK() OVER (PARTITION BY department_id ORDER BY hire_date) as ranking |
||||
FROM employees; |
||||
``` |
||||
|
||||
## Scalar Function |
||||
|
||||
A scalar function returns a single value each time it is invoked. It is based on the input value. |
||||
|
||||
```sql |
||||
SELECT UPPER(productName) FROM products; |
||||
``` |
||||
|
||||
## Stored Procedures |
||||
|
||||
Stored Procedures are a prepared SQL code that you can save so the code can be reused over and over again. |
||||
|
||||
```sql |
||||
CREATE PROCEDURE SelectAllProducts @Product varchar(50) |
||||
AS |
||||
SELECT * FROM products WHERE Product = @Product |
||||
GO; |
||||
``` |
||||
|
||||
## String Functions |
||||
|
||||
Functions that manipulate the string data types. For example, `LEFT()`, `LENGTH()`, `LOWER()`, etc. |
||||
|
||||
```sql |
||||
SELECT LEFT('This is a test', 4); |
||||
``` |
||||
|
||||
## Date Functions |
||||
|
||||
Functions that manipulate the date data types. For example, `GETDATE()`, `DATEADD()`, `DATEDIFF()`, etc. |
||||
|
||||
```sql |
||||
SELECT GETDATE() AS CurrentDateTime; |
||||
``` |
||||
Remember, not all types or functions are supported by every SQL distribution but most of them have some sort of equivalent. |
||||
@ -0,0 +1,52 @@ |
||||
# Creating Views |
||||
|
||||
In SQL, creating views can be achieved through the `CREATE VIEW` statement. A view is a virtual table based on the result-set of an SQL statement. It contains rows and columns from one or more tables. The syntax for the `CREATE VIEW` statement is: |
||||
|
||||
```sql |
||||
CREATE VIEW view_name AS |
||||
SELECT column1, column2, ... |
||||
FROM table_name |
||||
WHERE condition; |
||||
``` |
||||
|
||||
Here: |
||||
- `CREATE VIEW view_name` : It creates a new view that you define with `view_name`. |
||||
- `AS SELECT column1, column2 ...` : These are the columns you want in your view. You can choose one or more columns from one or more tables. |
||||
- `FROM table_name` : `table_name` is the name of the table from which you want to create the view. |
||||
- `WHERE` : It is an optional clause that you can use to specify conditions for displaying records. |
||||
|
||||
**Example:** |
||||
|
||||
Let's say you have a table named `Employees` having following data: |
||||
|
||||
| ID | NAME | SALARY | DEPARTMENT_ID | |
||||
|----|-------|--------|---------------| |
||||
| 1 | John | 3000 | 2 | |
||||
| 2 | Sue | 3500 | 3 | |
||||
| 3 | Phil | 4500 | 2 | |
||||
| 4 | Anna | 5000 | 1 | |
||||
|
||||
You can create a view that shows only the employees from department 2: |
||||
|
||||
```sql |
||||
CREATE VIEW Department2 AS |
||||
SELECT Name, Salary |
||||
FROM Employees |
||||
WHERE Department_ID = 2; |
||||
``` |
||||
|
||||
After running this statement, `Department2` will be a saved view in your database, and you can query it like you would with a standard table: |
||||
|
||||
```sql |
||||
SELECT * |
||||
FROM Department2; |
||||
``` |
||||
|
||||
This would bring up |
||||
|
||||
| NAME | SALARY | |
||||
|------|--------| |
||||
| John | 3000 | |
||||
| Phil | 4500 | |
||||
|
||||
In total, the `CREATE VIEW` statement is a useful command when you want to save a particular query and its result set for future use. This can simplify complex queries by breaking them up into manageable parts. |
||||
@ -0,0 +1,82 @@ |
||||
# Modifying Views |
||||
|
||||
In SQL, you can modify a VIEW in two ways: |
||||
|
||||
- Using CREATE OR REPLACE VIEW: This command helps you modify a VIEW but keeps the VIEW name intact. This is beneficial when you want to change the definition of the VIEW but do not want to change the VIEW name. |
||||
|
||||
- Using the DROP VIEW and then CREATE VIEW: In this method, you first remove the VIEW using the DROP VIEW command and then recreate the view using the new definition with the CREATE VIEW command. |
||||
|
||||
## Modifying VIEW Using CREATE OR REPLACE VIEW |
||||
|
||||
Syntax: |
||||
|
||||
```sql |
||||
CREATE OR REPLACE VIEW view_name AS |
||||
SELECT column1, column2, ... |
||||
FROM table_name |
||||
WHERE condition; |
||||
``` |
||||
|
||||
Example: |
||||
|
||||
```sql |
||||
CREATE OR REPLACE VIEW customer_view AS |
||||
SELECT customer_name, country |
||||
FROM customers |
||||
WHERE country='USA'; |
||||
``` |
||||
In this example, 'customer_view' will show the names and countries of customers only from the USA. |
||||
|
||||
## Modifying VIEW Using DROP VIEW and CREATE VIEW |
||||
|
||||
Syntax: |
||||
Drop the VIEW: |
||||
```sql |
||||
DROP VIEW view_name; |
||||
``` |
||||
Create a new VIEW: |
||||
```sql |
||||
CREATE VIEW view_name AS |
||||
SELECT column1, column2, ... |
||||
FROM table_name |
||||
WHERE condition; |
||||
``` |
||||
|
||||
Example: |
||||
Drop the VIEW |
||||
```sql |
||||
DROP VIEW customer_view; |
||||
``` |
||||
Create a new VIEW: |
||||
```sql |
||||
CREATE VIEW customer_view AS |
||||
SELECT customer_name, country |
||||
FROM customers |
||||
WHERE country='UK'; |
||||
``` |
||||
In this example, we first removed 'customer_view'. Then, we created it again with the new definition where it now shows the names and countries of the customers only from the UK. |
||||
|
||||
**CAUTION**: If other views, stored procedures, or programs depend on this view, they will be affected after you drop the view. For this reason, using CREATE OR REPLACE VIEW is generally safer. |
||||
|
||||
## Modifying Data through VIEW |
||||
|
||||
In some cases, you can modify the data of the underlying tables via a VIEW. |
||||
|
||||
Syntax: |
||||
|
||||
```sql |
||||
UPDATE view_name |
||||
SET column1 = value1, column2 = value2, ... |
||||
WHERE condition; |
||||
``` |
||||
|
||||
Example: |
||||
|
||||
```sql |
||||
UPDATE customer_view |
||||
SET country = 'USA' |
||||
WHERE customer_name = 'John Doe'; |
||||
``` |
||||
This command will update the country of 'John Doe' to 'USA' in both the VIEW and the underlying table. |
||||
|
||||
However, not every VIEW is updatable. You can only modify the data if the VIEW you're modifying is a simple VIEW that returns results from a single table without any aggregation or complex clauses. If you attempt to modify a complex view (i.e., it includes JOIN, GROUP BY, HAVING, DISTINCT), you will get an error. |
||||
@ -0,0 +1,31 @@ |
||||
# Dropping Views |
||||
|
||||
"Dropping" in SQL is the process of deleting an existing database object. In the context of views, "dropping" refers to deleting an existing view from the database. Once a view is dropped, it cannot be used any longer until it is recreated with the same or new definition. If you're going to drop a view, ensure it's not being used anywhere in your application or it will lead to errors. |
||||
|
||||
## Dropping Views |
||||
|
||||
You can drop a view in SQL using the `DROP VIEW` statement. The `DROP VIEW` statement removes one or more views from the database. You specify the name of the view that you want to remove after the `DROP VIEW` clause. |
||||
|
||||
Here is the basic syntax to drop an existing view: |
||||
|
||||
```sql |
||||
DROP VIEW view_name; |
||||
``` |
||||
|
||||
To drop multiple views in a single command, you use a list of comma-separated views. |
||||
|
||||
```sql |
||||
DROP VIEW view_name1, view_name2, ..., view_name_n; |
||||
``` |
||||
|
||||
**Note**: Be careful when dropping views. Once a view is dropped, all the permissions granted on it will also be dropped. |
||||
|
||||
Before dropping a view, you can check if the view exists by using the `IF EXISTS` parameter. If you drop a view that does not exist, you will get an error. To prevent this, you can use the `IF EXISTS` parameter. |
||||
|
||||
Here is how you do it: |
||||
|
||||
```sql |
||||
DROP VIEW IF EXISTS view_name; |
||||
``` |
||||
|
||||
In this case, if the view exists, it will be dropped. If the view does not exist, nothing happens and you don't get an error. |
||||
@ -0,0 +1,54 @@ |
||||
# Views |
||||
|
||||
SQL views are virtual tables that do not store data directly. They are essentially a saved SQL query and can pull data from multiple tables or just present the data from one table in a different way. |
||||
|
||||
## Creating Views |
||||
|
||||
You can create a view using the `CREATE VIEW` statement. In the following example, a new view named `CustomerView` is created which contains customer's ID, name, and address from the `Customers` table: |
||||
|
||||
```sql |
||||
CREATE VIEW CustomerView AS |
||||
SELECT CustomerID, Name, Address |
||||
FROM Customers; |
||||
``` |
||||
|
||||
## Querying Views |
||||
|
||||
After a view has been created, it can be used in the `FROM` clause of a `SELECT` statement, as if it's an actual table. For instance, to select all from `CustomerView`: |
||||
|
||||
```sql |
||||
SELECT * |
||||
FROM CustomerView; |
||||
``` |
||||
|
||||
## Updating Views |
||||
|
||||
The `CREATE OR REPLACE VIEW` statement is used to update a view. Consider the `CustomerView` we created earlier. If we want to include the customer's phone, we can update it as follows: |
||||
|
||||
```sql |
||||
CREATE OR REPLACE VIEW CustomerView AS |
||||
SELECT CustomerID, Name, Address, Phone |
||||
FROM Customers; |
||||
``` |
||||
|
||||
## Dropping Views |
||||
|
||||
To delete a view, use the `DROP VIEW` statement: |
||||
|
||||
```sql |
||||
DROP VIEW CustomerView; |
||||
``` |
||||
|
||||
Keep in mind that not all database systems support the `CREATE OR REPLACE VIEW` statement. Also, the updatability of a view depends on whether it includes functions, expressions, or multiple tables. Some databases might not let you update a view at all. |
||||
|
||||
## Restrictions |
||||
|
||||
There are a few restrictions to bear in mind when working with views. SQL views can't: |
||||
|
||||
- Contain a `ORDER BY` clause in the view definition |
||||
- Be indexed |
||||
- Have triggers or default values |
||||
|
||||
Each database may have its own specific limitations and capabilities with using views, so always refer to the official documentation for more information. |
||||
|
||||
Note: The above examples use a hypothetical `Customers` table. Replace this with your actual table name when trying these in your environment. |
||||
@ -0,0 +1,48 @@ |
||||
# Managing Indexes |
||||
|
||||
Indexes can drastically speed up data retrieval in SQL databases by allowing the database to immediately locate the data needed without having to scan the entire database. However, these additional data structures also consume storage, and maintaining them can slow down any create, update, or delete operations, hence the need to manage them appropriately. |
||||
|
||||
## Creating Indexes |
||||
|
||||
To create an index, you use the `CREATE INDEX` command followed by the index name, the table name, and the columns you want to use in the index. |
||||
|
||||
```sql |
||||
CREATE INDEX index_name |
||||
ON table_name(column_name); |
||||
``` |
||||
|
||||
## Removing Indexes |
||||
|
||||
If an index is no longer required or if it's causing performance issues due to too much storage consumption, it can be dropped using the `DROP INDEX` command. |
||||
|
||||
```sql |
||||
DROP INDEX index_name; |
||||
``` |
||||
|
||||
## Listing Indexes |
||||
|
||||
You can get a list of all the indexes on a table using the `SHOW INDEXES` command. |
||||
|
||||
```sql |
||||
SHOW INDEXES IN table_name; |
||||
``` |
||||
|
||||
Remember that most SQL databases automatically create indexes for primary keys, and they do not need to be managed manually. |
||||
|
||||
## Modifying Indexes |
||||
|
||||
Modifying an existing index often means dropping the old index and creating a new one. PostgreSQL, MySQL, and MS SQL Server provide a way to reindex without dropping and recreating them manually. |
||||
|
||||
For example, in PostgreSQL: |
||||
|
||||
```sql |
||||
REINDEX INDEX index_name; |
||||
``` |
||||
|
||||
## Indexes and Performance |
||||
|
||||
While indexes can improve read speed, they also slow down write operations because each write must also update the index. That's why it's essential to find a balance between the number of indexes and database performance. Too many indexes can negatively impact performance. |
||||
|
||||
Therefore, you should only create indexes when they are likely to be needed and when they will have a significant impact on improving query performance. You can use the SQL Server Profiler, MySQL's slow query log, or other database-specific tools to identify the queries that are running slow, and then create indexes to optimize those queries. Regularly monitor your database performance to make sure that the indexes are still needed and that they are providing the expected improvements. |
||||
|
||||
Add indexes strategically and purposefully, and do regular cleanups of any unnecessary indexes. |
||||
@ -0,0 +1,66 @@ |
||||
# Query Optimization |
||||
|
||||
Query optimization is a function of SQL that involves tuning and optimizing a SQL statement so that the system executes it in the fastest and most efficient way possible. It includes optimizing the costs of computation, communication, and disk I/O. |
||||
|
||||
The primary approaches of query optimization involve the following: |
||||
|
||||
## Rewriting Queries |
||||
|
||||
This means changing the original SQL query to an equivalent one which requires fewer system resources. It's usually done automatically by the database system. |
||||
|
||||
For instance, let's say we have a query as follows: |
||||
|
||||
```sql |
||||
SELECT * |
||||
FROM Customers |
||||
WHERE state = 'New York' AND city = 'New York'; |
||||
``` |
||||
|
||||
The above query can be rewritten using a subquery for better optimization: |
||||
|
||||
```sql |
||||
SELECT * |
||||
FROM Customers |
||||
WHERE state = 'New York' |
||||
AND city IN (SELECT city |
||||
FROM Customers |
||||
WHERE city = 'New York'); |
||||
``` |
||||
|
||||
## Choosing the right index |
||||
|
||||
Indexes are used to find rows with specific column values quickly. Without an index, SQL has to begin with the first row and then read through the entire table to find the appropriate rows. The larger the table, the more costly the operation. Choosing a right and efficient index greatly influence on query performance. |
||||
|
||||
For example, |
||||
|
||||
```sql |
||||
CREATE INDEX index_name |
||||
ON table_name (column1, column2, ...); |
||||
``` |
||||
|
||||
## Fine-tuning Database Design |
||||
|
||||
Improper database schema designs could result in poor query performances. While not strictly a part of query optimization, tuning the database design can speed up the query execution time drastically. |
||||
|
||||
Changes such as the separation of specific data to different tables (Normalization), combining redundant data (Denormalization), or changing the way how tables are linked (Optimized Join Operations), can be implemented to optimize the schema. |
||||
|
||||
## Use of SQL Clauses wisely |
||||
|
||||
The usage of certain SQL clauses can help in query optimization like LIMIT, BETWEEN etc. |
||||
|
||||
Example, |
||||
|
||||
```sql |
||||
SELECT column1, column2 |
||||
FROM table_name |
||||
WHERE condition |
||||
LIMIT 10; |
||||
``` |
||||
|
||||
## System Configuration |
||||
|
||||
Many database systems allow you to configure system parameters that control its behavior during query execution. For instance, in MySQL, you can set parameters like `sort_buffer_size` or `join_buffer_size` to tweak how MySQL would use memory during sorting and joining operations. |
||||
|
||||
In PostgreSQL, you can set `work_mem` to control how much memory is utilized during operations such as sorting and hashing. |
||||
|
||||
Always remember the goal of query optimization is to lessen the system resources usage in terms of memory, CPU time, and thus improve the query performance. |
||||
@ -0,0 +1,72 @@ |
||||
# Indexes |
||||
|
||||
An index in SQL is a database object which is used to improve the speed of data retrieval operations on a database table. Similarly to how an index in a book helps you find information quickly without reading the entire book, an index in a database helps the database software find data quickly without scanning the entire table. |
||||
|
||||
## Clustered Index |
||||
|
||||
A clustered index determines the physical order of data inside a table. It sorts and stores the data rows in the table based on their key values. There can be only one clustered index per table. |
||||
|
||||
Creating a clustered index: |
||||
|
||||
```sql |
||||
CREATE CLUSTERED INDEX index_name |
||||
ON table_name (column_name); |
||||
``` |
||||
|
||||
## Non-Clustered Index |
||||
|
||||
A non-clustered index doesn’t sort the physical data inside the table. Instead, it creates a separate object within a table which points back to the original table rows after creating. You can create numerous non-clustered indexes per table. |
||||
|
||||
Creating a non-clustered index: |
||||
|
||||
```sql |
||||
CREATE NONCLUSTERED INDEX index_name |
||||
ON table_name (column_name); |
||||
``` |
||||
|
||||
## Indexes on Multiple Columns |
||||
|
||||
An index can be built on more than one column of a table, which results in index entries having values of multiple columns. This is known as a composite index. |
||||
|
||||
Creating a composite index: |
||||
|
||||
```sql |
||||
CREATE INDEX index_name |
||||
ON table_name (column1, column2); |
||||
``` |
||||
|
||||
## Unique Indexes |
||||
|
||||
A unique index doesn't allow any field to have duplicate values if the field is unique indexed. If a primary key is defined, a unique index can be applied automatically. |
||||
|
||||
Creating a unique index: |
||||
|
||||
```sql |
||||
CREATE UNIQUE INDEX index_name |
||||
ON table_name (column_name); |
||||
``` |
||||
|
||||
## Explicit vs Implicit Indexes |
||||
|
||||
Indexes explicitly created by users are known as explicit indexes, while indexes automatically created by SQL Server when a primary key or unique constraint is defined are known as implicit indexes. |
||||
|
||||
Creating an explicit index: |
||||
|
||||
```sql |
||||
CREATE INDEX index_name |
||||
ON table_name (column_name); |
||||
``` |
||||
|
||||
## Full-Text Indexes |
||||
|
||||
If you're dealing with text searching within a large string of text, full-text indexes are especially helpful. These indexes do not work using a standard comparison search but instead use word-breakers, filters, and noise-words (stop words). |
||||
|
||||
Creating a full-text index: |
||||
|
||||
```sql |
||||
CREATE FULLTEXT INDEX ON table_name |
||||
(column_name) |
||||
KEY INDEX index_name; |
||||
``` |
||||
|
||||
Please note that the creation and maintenance of indexes involve a trade-off between query speed and update costs. Indexes speed up retrieval at the expense of slower updates and increased storage space. |
||||
@ -0,0 +1,9 @@ |
||||
# ACID |
||||
|
||||
ACID are the four properties of relational database systems that help in making sure that we are able to perform the transactions in a reliable manner. It's an acronym which refers to the presence of four properties: atomicity, consistency, isolation and durability |
||||
|
||||
Visit the following resources to learn more: |
||||
|
||||
- [What is ACID Compliant Database?](https://retool.com/blog/whats-an-acid-compliant-database/) |
||||
- [What is ACID Compliance?: Atomicity, Consistency, Isolation](https://fauna.com/blog/what-is-acid-compliance-atomicity-consistency-isolation) |
||||
- [ACID Explained: Atomic, Consistent, Isolated & Durable](https://www.youtube.com/watch?v=yaQ5YMWkxq4) |
||||
@ -0,0 +1,45 @@ |
||||
# Transaction Isolation Levels |
||||
|
||||
SQL supports four transaction isolation levels, each differing in how it deals with concurrency and locks to protect the integrity of the data. Each level makes different trade-offs between consistency and performance. Here is a brief of these isolation levels with relevant SQL statements. |
||||
|
||||
1. **READ UNCOMMITTED** |
||||
This is the lowest level of isolation. One transaction may read not yet committed changes made by other transaction, also known as "Dirty Reads". Here's an example of how to set this level: |
||||
|
||||
```sql |
||||
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; |
||||
BEGIN TRANSACTION; |
||||
-- Execute your SQL commands here |
||||
COMMIT; |
||||
``` |
||||
|
||||
2. **READ COMMITTED** |
||||
A transaction only sees data changes committed before it started, averting "Dirty Reads". However, it may experience "Non-repeatable Reads", i.e. if a transaction reads the same row multiple times, it might get a different result each time. Here's how to set this level: |
||||
|
||||
```sql |
||||
SET TRANSACTION ISOLATION LEVEL READ COMMITTED; |
||||
BEGIN TRANSACTION; |
||||
-- Execute your SQL commands here |
||||
COMMIT; |
||||
``` |
||||
|
||||
3. **REPEATABLE READ** |
||||
Here, once a transaction reads a row, any other transaction's writes (changes) onto those rows are blocked until the first transaction is finished, preventing "Non-repeatable Reads". However, "Phantom Reads" may still occur. Here's how to set this level: |
||||
|
||||
```sql |
||||
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; |
||||
BEGIN TRANSACTION; |
||||
-- Execute your SQL commands here |
||||
COMMIT; |
||||
``` |
||||
|
||||
4. **SERIALIZABLE** |
||||
This is the highest level of isolation. It avoids "Dirty Reads", "Non-repeatable Reads" and "Phantom Reads". This is done by fully isolating one transaction from others: read and write locks are acquired on data that are used in a query, preventing other transactions from accessing the respective data. Here's how to set this level: |
||||
|
||||
```sql |
||||
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE; |
||||
BEGIN TRANSACTION; |
||||
-- Execute your SQL commands here |
||||
COMMIT; |
||||
``` |
||||
|
||||
Remember, higher levels of isolation usually provide more consistency but can potentially decrease performance due to increased waiting times for locks. |
||||
@ -0,0 +1,43 @@ |
||||
# BEGIN |
||||
|
||||
In SQL, a transaction refers to a unit of work performed against a database. Transactions in SQL are used to ensure the integrity of the database. The keywords used in SQL to control the transactions are `BEGIN`, `COMMIT`, `ROLLBACK`. |
||||
|
||||
## BEGIN |
||||
|
||||
In the context of SQL transactions, `BEGIN` is a keyword used to start a transaction. It marks the point at which the data referenced by a connection is logically consistent. After the `BEGIN` statement, the transaction is considered to be "open" and remains so until it is committed or rolled back. |
||||
|
||||
Once you've initiated a transaction with `BEGIN`, all the subsequent SQL statements will be a part of this transaction until an explicit `COMMIT` or `ROLLBACK` is given. |
||||
|
||||
## Syntax |
||||
|
||||
The syntax to start a transaction is: |
||||
```sql |
||||
BEGIN TRANSACTION; |
||||
``` |
||||
or simply, |
||||
```sql |
||||
BEGIN; |
||||
``` |
||||
## Example |
||||
|
||||
Below is a simple example of using `BEGIN` in SQL: |
||||
|
||||
```sql |
||||
BEGIN; |
||||
|
||||
INSERT INTO Customers (CustomerName, ContactName, Address, City, PostalCode, Country) |
||||
VALUES ('Cardinal', 'Tom B. Erichsen', 'Skagen 21', 'Stavanger', '4006', 'Norway'); |
||||
|
||||
COMMIT; |
||||
``` |
||||
|
||||
In this example: |
||||
- `BEGIN;` marks the start of the transaction. |
||||
- The `INSERT` statement adds a new row of data to the `Customers` table. |
||||
- `COMMIT;` ends the transaction and permanently saves the changes made during this transaction. |
||||
|
||||
Note: If something goes wrong with one of the SQL statements within the transaction (after the `BEGIN;` statement), you can choose to `ROLLBACK` the transaction, which means canceling all the changes made in this transaction up to the point of error. |
||||
|
||||
## Conclusion |
||||
|
||||
In summary, `BEGIN` in SQL is used to start a transaction, which enables modifications done in a database to be viewed as a logically coherent occurrence. |
||||
@ -0,0 +1,39 @@ |
||||
# COMMIT |
||||
|
||||
The SQL COMMIT command is used to save all the modifications made by the current transaction to the database. A COMMIT command ends the current transaction and makes permanent all changes performed in the transaction. It is a way of ending your transaction and saving your changes to the database. |
||||
|
||||
After the SQL COMMIT statement is executed, it can not be rolled back, which means you can't undo the operations. COMMIT command is used when the user is satisfied with the changes made in the transaction, and these changes can now be made permanent in the database. |
||||
|
||||
## Syntax: |
||||
|
||||
```sql |
||||
COMMIT; |
||||
``` |
||||
In some databases, if AUTOCOMMIT is enabled (which is typically the default setting), then every single SQL statement is treated as a transaction and automatically committed right after it is executed. |
||||
|
||||
Example: |
||||
|
||||
Imagine you have a transaction that transfers money from Account A to Account B. The SQL might look something like this: |
||||
|
||||
```sql |
||||
START TRANSACTION; |
||||
UPDATE Account SET amount = amount - 2000 WHERE name = 'A'; |
||||
UPDATE Account SET amount = amount + 2000 WHERE name = 'B'; |
||||
COMMIT; |
||||
``` |
||||
In this transaction, $2000 is transferred from account 'A' to account 'B'. The COMMIT statement makes these changes permanent in the database. |
||||
|
||||
However, keep in mind that if there was an error during this transaction (for instance if Account A did not have enough money), you'd want to ROLLBACK the transaction, not COMMIT, to undo any changes made before the error occurred. |
||||
|
||||
## Syntax with ROLLBACK: |
||||
|
||||
```sql |
||||
START TRANSACTION; |
||||
UPDATE Account SET amount = amount - 2000 WHERE name = 'A'; |
||||
UPDATE Account SET amount = amount + 2000 WHERE name = 'B'; |
||||
IF @@ERROR != 0 |
||||
ROLLBACK |
||||
ELSE |
||||
COMMIT; |
||||
``` |
||||
Here, if @@ERROR is not 0, the transaction will be rolled back. Otherwise, the transaction will be committed. |
||||
@ -0,0 +1,49 @@ |
||||
# ROLLBACK |
||||
|
||||
The `ROLLBACK` command is a transactional control language (TCL) instruction that undoes an unsuccessful or unsatisfactory running transaction. This process also applies to SQL Server where all individual statements in SQL Server are treated as a single atomic transaction. |
||||
|
||||
When a `ROLLBACK` command is issued, all the operations (such as Insert, Delete, Update, etc.) are undone and the database is restored to its initial state before the transaction started. |
||||
|
||||
## When to use `ROLLBACK` |
||||
|
||||
1. If the transaction is unacceptable or unsuccessful. |
||||
2. If you want to revert the unwanted changes. |
||||
|
||||
Here is a basic example: |
||||
|
||||
```sql |
||||
BEGIN TRANSACTION; |
||||
|
||||
-- This would delete all rows from the table. |
||||
DELETE FROM Employee; |
||||
|
||||
-- Oh no! That's not what I wanted. Let's roll that back. |
||||
ROLLBACK; |
||||
``` |
||||
|
||||
In this example, the `ROLLBACK` command would restore all deleted data into the `Employee` table. |
||||
|
||||
SQL also allows the usage of `SAVEPOINT`s along with the `ROLLBACK` command, which allows rolling back to a specific point in a transaction, instead of rolling back the entire transaction. |
||||
|
||||
Here is an example of using `SAVEPOINT`s: |
||||
|
||||
```sql |
||||
BEGIN TRANSACTION; |
||||
|
||||
-- Adding new employee. |
||||
INSERT INTO Employee(ID, Name) VALUES(1, 'John'); |
||||
|
||||
-- Create a savepoint to be able to roll back to this point. |
||||
SAVEPOINT SP1; |
||||
|
||||
-- Oh no! I made a mistake creating this employee. Let's roll back to the savepoint. |
||||
ROLLBACK TO SAVEPOINT SP1; |
||||
|
||||
-- Now I can try again. |
||||
INSERT INTO Employee(ID, Name) VALUES(1, 'Jack'); |
||||
|
||||
-- Commit the changes. |
||||
COMMIT; |
||||
``` |
||||
|
||||
In this example, `ROLLBACK TO SAVEPOINT SP1` would undo the first insert into the `Employee` table while preserving the state of the database as it was at the savepoint `SP1`. So, the second insert command would properly add 'Jack' in place of 'John'. |
||||
@ -0,0 +1,60 @@ |
||||
# SAVEPOINT |
||||
|
||||
A savepoint is a way of implementing subtransactions (nested transactions) within a relational database management system by indicating a particular point within a transaction that a user can "roll back" to in case of failure. The main property of a savepoint is that it enables you to create a rollback segment within a transaction. This allows you to revert the changes made to the database after the Savepoint without having to discard the entire transaction. |
||||
|
||||
A Savepoint might be used in instances where if a particular operation fails, you would like to revert the database to the state it was in before the operation was attempted, but you do not want to give up on the entire transaction. |
||||
|
||||
## Savepoint Syntax |
||||
|
||||
The general syntax for `SAVEPOINT`: |
||||
|
||||
```sql |
||||
SAVEPOINT savepoint_name; |
||||
``` |
||||
|
||||
## Use of Savepoint |
||||
|
||||
Here is the basic usage of savepoint: |
||||
|
||||
```sql |
||||
START TRANSACTION; |
||||
INSERT INTO Table1 (Column1) VALUES ('Value1'); |
||||
|
||||
SAVEPOINT SP1; |
||||
|
||||
INSERT INTO Table1 (Column1) VALUES ('Value2'); |
||||
|
||||
ROLLBACK TO SP1; |
||||
|
||||
COMMIT; |
||||
``` |
||||
|
||||
In this example, an initial `INSERT` statement is performed before a Savepoint named `SP1` is created. Another `INSERT` statement is called and then `ROLLBACK TO SP1` is executed. This means all changes between the creation of `SP1` and `ROLLBACK TO SP1` are reverted. After that, 'COMMIT' is used to permanently store the changes made by the first `INSERT` statement. |
||||
|
||||
## Release Savepoint |
||||
|
||||
The `RELEASE SAVEPOINT` deletes a savepoint within a transaction. |
||||
|
||||
Here’s the syntax: |
||||
|
||||
```sql |
||||
RELEASE SAVEPOINT savepoint_name; |
||||
``` |
||||
|
||||
The action of releasing a savepoint removes the named savepoint from the set of savepoints of the current transaction. No changes are undone. |
||||
|
||||
## Remove Savepoint |
||||
|
||||
The `ROLLBACK TO SAVEPOINT` removes a savepoint within a transaction. |
||||
|
||||
Here’s the syntax: |
||||
|
||||
```sql |
||||
ROLLBACK TRANSACTION TO savepoint_name; |
||||
``` |
||||
|
||||
This statement rolls back a transaction to the named savepoint without terminating the transaction. |
||||
|
||||
Please note, savepoint names are not case sensitive and must obey the syntax rules of the server. |
||||
|
||||
If you found this information useful and want to learn more about topics like transactions, SQL commands, normalisation and more, consider subscribing to our mailing list. You’ll receive regular updates and exclusive content to help you become a better SQL developer. Please contact me if you have any further queries. |
||||
@ -0,0 +1,52 @@ |
||||
# Transactions |
||||
|
||||
A `transaction` in SQL is a unit of work that is performed against a database. Transactions are units or sequences of work accomplished in a logical order, whether in a manual fashion by a user or automatically by some sort of a database program. |
||||
|
||||
Transactions are used to ensure data integrity and to handle database errors while processing. SQL transactions are controlled by the following commands: |
||||
|
||||
- `BEGIN TRANSACTION` |
||||
- `COMMIT` |
||||
- `ROLLBACK` |
||||
|
||||
## BEGIN TRANSACTION |
||||
|
||||
This command is used to start a new transaction. |
||||
|
||||
```sql |
||||
BEGIN TRANSACTION; |
||||
``` |
||||
|
||||
## COMMIT |
||||
|
||||
The `COMMIT` command is the transactional command used to save changes invoked by a transaction to the database. |
||||
|
||||
```sql |
||||
COMMIT; |
||||
``` |
||||
When you commit the transaction, the changes are permanently saved in the database. |
||||
|
||||
## ROLLBACK |
||||
|
||||
The `ROLLBACK` command is the transactional command used to undo transactions that have not already been saved to the database. |
||||
|
||||
```sql |
||||
ROLLBACK; |
||||
``` |
||||
|
||||
When you roll back a transaction, all changes made since the last commit in the database are undone, and the database is rolled back to the state it was in at the last commit. |
||||
|
||||
## Transaction Example |
||||
```sql |
||||
BEGIN TRANSACTION; |
||||
|
||||
UPDATE Accounts SET Balance = Balance - 100 WHERE id = 1; |
||||
UPDATE Accounts SET Balance = Balance + 100 WHERE id = 2; |
||||
|
||||
IF @@ERROR = 0 |
||||
COMMIT; |
||||
ELSE |
||||
ROLLBACK; |
||||
``` |
||||
In this example, we are transferring 100 units from account 1 to account 2 inside a transaction. If any errors occurred during any of the update statements (captured by `@@ERROR`), the transaction is rolled back, otherwise, it is committed. |
||||
|
||||
Remember that for the transaction to be successful, all commands must execute successfully. If any command fails, the transaction fails, the database state is left unchanged and an error is returned. |
||||
@ -0,0 +1,83 @@ |
||||
# Data Integrity Constraints |
||||
|
||||
SQL constraints are used to specify rules for the data in a table. They ensure the accuracy and reliability of the data within the table. If there is any violation between the constraint and the action, the action is aborted by the constraint. |
||||
|
||||
Constraints are classified into two types: column level and table level. Column level constraints apply to individual columns whereas table level constraints apply to the entire table. |
||||
|
||||
Here are the commonly used constraints: |
||||
|
||||
## 1. NOT NULL |
||||
|
||||
The `NOT NULL` constraint enforces a field to always contain a value. This means that you cannot insert a new record or update a record without adding a value to this field. |
||||
|
||||
**Example:** |
||||
|
||||
```sql |
||||
CREATE TABLE Employees ( |
||||
ID int NOT NULL, |
||||
Name varchar(255) NOT NULL, |
||||
Age int |
||||
); |
||||
``` |
||||
|
||||
## 2. UNIQUE |
||||
|
||||
The `UNIQUE` constraint ensures that all values in a column are different, thus, prevents duplicate values in a column. |
||||
|
||||
**Example:** |
||||
|
||||
```sql |
||||
CREATE TABLE Employees ( |
||||
ID int NOT NULL UNIQUE, |
||||
Name varchar(255) NOT NULL, |
||||
Age int |
||||
); |
||||
``` |
||||
|
||||
## 3. PRIMARY KEY |
||||
|
||||
The `PRIMARY KEY` constraint uniquely identifies each record in a database table. This constraint provides uniqueness for the column or set of columns, and not null. |
||||
|
||||
**Example:** |
||||
|
||||
```sql |
||||
CREATE TABLE Employees ( |
||||
ID int NOT NULL, |
||||
Name varchar(255) NOT NULL, |
||||
Age int, |
||||
PRIMARY KEY (ID) |
||||
); |
||||
``` |
||||
|
||||
## 4. FOREIGN KEY |
||||
|
||||
The `FOREIGN KEY` constraint prevents actions that would destroy links between tables. It maintains referential integrity by requiring that a value inserted into a foreign key column exists in the referenced primary key. |
||||
|
||||
**Example:** |
||||
|
||||
```sql |
||||
CREATE TABLE Orders ( |
||||
OrderID int NOT NULL, |
||||
OrderNumber int NOT NULL, |
||||
EmployeeID int, |
||||
PRIMARY KEY (OrderID), |
||||
FOREIGN KEY (EmployeeID) REFERENCES Employees(ID) |
||||
); |
||||
``` |
||||
|
||||
## 5. CHECK |
||||
|
||||
The `CHECK` constraint ensures that all values in a field satisfy a condition. It enables a condition to check the value being entered into a record. |
||||
|
||||
**Example:** |
||||
|
||||
```sql |
||||
CREATE TABLE Employees ( |
||||
ID int NOT NULL, |
||||
Name varchar(255) NOT NULL, |
||||
Age int, |
||||
CHECK (Age>=18) |
||||
); |
||||
``` |
||||
|
||||
Each constraint has its own purpose and usage, utilizing them effectively helps maintain the accuracy and integrity of the data. |
||||
@ -0,0 +1,46 @@ |
||||
# GRANT and REVOKE |
||||
|
||||
In SQL, `GRANT` and `REVOKE` are Data Control Language (DCL) commands used for providing and removing user privileges respectively. |
||||
|
||||
## GRANT |
||||
|
||||
The `GRANT` statement allows database administrators to grant permissions or privileges on a database object to users. There are various types of privileges like SELECT, INSERT, UPDATE, DELETE, REFERENCES, ALL. |
||||
|
||||
You can use the `GRANT` statement as follows: |
||||
|
||||
```sql |
||||
GRANT privilege_name |
||||
ON object_name |
||||
TO {user_name |PUBLIC |role_name} |
||||
[WITH GRANT OPTION]; |
||||
``` |
||||
|
||||
Example: |
||||
|
||||
```sql |
||||
GRANT SELECT ON employees TO user1; |
||||
``` |
||||
|
||||
In this example, `user1` is granted permission to read/perform SELECT operations on the `employees` table. |
||||
|
||||
## REVOKE |
||||
|
||||
The `REVOKE` statement can be used when we want to revoke some or all of the privileges that were assigned earlier to a user or a group of users. The syntax for using the `REVOKE` command is similar to the `GRANT` command. |
||||
|
||||
Here's the syntax: |
||||
|
||||
```sql |
||||
REVOKE privilege_name |
||||
ON object_name |
||||
FROM {user_name |PUBLIC |role_name} |
||||
``` |
||||
|
||||
Example: |
||||
|
||||
```sql |
||||
REVOKE SELECT ON employees FROM user1; |
||||
``` |
||||
|
||||
In this example, `user1` is revoked from the permission to read/perform SELECT operations on the `employees` table. |
||||
|
||||
Permission management is an important aspect of database management, understanding, and using `GRANT` and `REVOKE` operations help in maintaining the integrity and security of your data in SQL. |
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in new issue